Reinforcement Learning · AI Agents · LLM Reasoning
SCOPE: Self-Play RL That Trains LLMs on Open-Ended Tasks
SCOPE co-evolves a task-writing Challenger and a retrieval Solver, judged by a frozen copy of the base model, lifting eight open-ended benchmarks by up to +10.4 points with zero curated prompts.
Quick answer
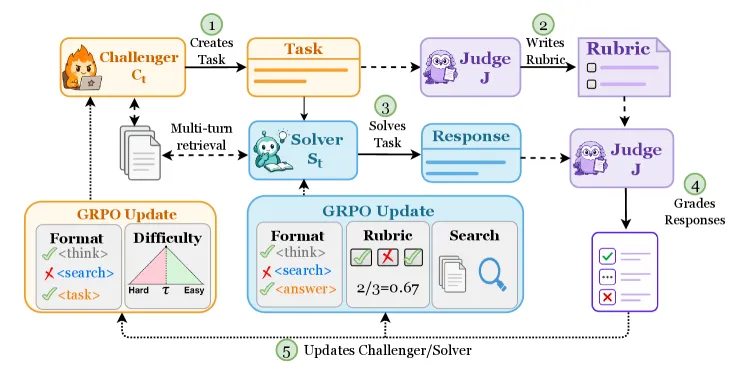
SCOPE lets a 7-8B language model improve on open-ended tasks without any human-written prompts, gold answers, or a stronger external judge. It splits one base model into three roles: a Challenger that writes document-grounded questions, a Solver that answers them through multi-turn retrieval, and a frozen Judge (a snapshot of the starting model) that builds a rubric from the source document and scores the answer. Challenger and Solver are trained against each other.
The headline: across eight open-ended benchmarks, SCOPE raises three different base models by up to +10.4 points (Qwen2.5-7B, 24.4 → 34.8 after three iterations), and it matches or beats GRPO_data, a baseline trained on roughly 9K curated prompts, despite SCOPE using none.
How the co-evolution loop works
The clever part is what they did with the judge problem. Self-play on math or code works because answers are rule-checkable: you can verify a proof or run a unit test. Open-ended tasks (deep research, scholarly QA, planning, creative writing) have no such oracle, so prior work fell back on curated datasets or frontier-model judges like GPT-4. SCOPE removes both crutches.
- Challenger samples a document, then writes a task that should be answerable from that document. It is rewarded for producing tasks that are hard but solvable: not so trivial the Solver aces them, not so impossible no one can.
- Solver answers via retrieval-augmented generation over a corpus, taking multiple search turns.
- Judge is the original model, frozen at step zero. It sees the source document the Challenger used, derives a task-specific rubric from it, and grades the Solver against that rubric. Grounding the rubric in a real document is what lets a frozen, non-frontier model give usable reward signal.
Training alternates: optimize the Challenger to keep difficulty in the productive band, then optimize the Solver to clear it. Both drift upward together, which is the “co-evolving policies” in the name.
Key results
- Up to +10.4 points on eight open-ended benchmarks (DRB-RACE, ResearchRubrics, ResearchQA, SQA-CS-V2, ResearchPlanGen, HealthBench, WildBench, Arena-Hard-CW), averaged across Qwen2.5-7B, Qwen3-8B, and OLMo-3-7B.
- Qwen2.5-7B: 24.4 → 34.8 (+10.4) after iteration 3;
GRPO_datareaches 33.4, so SCOPE wins despite zero curated prompts. - Qwen3-8B: 37.7 → 43.1 (+5.4);
GRPO_data41.5, so SCOPE is ahead. - OLMo-3-7B: 30.7 → 38.5 (+7.8);
GRPO_data39.0. Here the curated baseline edges SCOPE slightly, the one model where SCOPE does not lead on the main metric. - Held-out short-form QA: gains up to +13.8 points across seven QA benchmarks, and on Qwen3-8B SCOPE hits 61.8 vs
GRPO_data’s 60.7. The open-ended training transfers to clean factual QA rather than overfitting to verbose answers.
The transfer to short-form QA is the result I’d weight most. A common failure mode of rubric-graded RL is that the model learns to write longer, hedged answers that score well on rubrics but add nothing factual. SCOPE improving on short-form QA suggests it is learning to retrieve and ground, not just to pad.
Why a frozen judge is the interesting bet
Using the frozen initial model as judge is a deliberate constraint, not a limitation they tolerated. If the judge co-evolved with the Solver, you’d risk reward hacking: the Solver and judge could collude on a shared shortcut. Freezing the judge keeps the target stationary. The trade is obvious: your reward signal can never be smarter than your day-zero model. SCOPE’s bet is that document-grounded rubrics make a mediocre judge good enough, because the hard part (knowing the right answer) is offloaded to the source document rather than the judge’s parametric knowledge.
That bet mostly pays off, but it caps the method. You will not bootstrap a 7B model to frontier quality this way; you bootstrap it to the ceiling its own grounded-judgment can certify.
Limits and open questions
- Rubric generation is the bottleneck, by the authors’ own diagnosis. The whole loop is only as good as the rubrics the frozen judge writes from documents; better rubric synthesis is the obvious lever.
- OLMo-3-7B is the cautionary data point:
GRPO_data(39.0) beat SCOPE (38.5) there. Curated prompts still win sometimes, so “no data needed” is a strong claim that holds on average, not universally. - Corpus dependence: everything is document-grounded, so the achievable skill is bounded by the retrieval corpus. Open-ended creativity that isn’t answerable from a document has no clear path here.
- Scale untested in this report: results are 7-8B only. Whether co-evolution stays stable at 70B+, and whether a frozen judge stays useful there, is open.
Who should skip it: if your task already has a verifier (math, code, structured extraction), plain GRPO with that verifier is simpler and likely stronger. SCOPE earns its complexity specifically when no verifier exists and you refuse to pay for a frontier judge.
FAQ
How is SCOPE different from RLAIF or using GPT-4 as a judge?
SCOPE never calls an external or stronger model. Its judge is a frozen copy of the same base model being trained, and it grades against a rubric derived from the source document rather than the judge’s own opinion. That makes the reward cheaper and removes the dependence on a frontier API, at the cost of a reward ceiling tied to your starting model.
Does SCOPE actually beat GRPO trained on curated data?
On average yes. SCOPE matches or exceeds GRPO_data (trained on ~9K curated prompts) on Qwen2.5-7B and Qwen3-8B, and on held-out short-form QA. The exception is OLMo-3-7B, where the curated baseline scored 39.0 to SCOPE’s 38.5. So the “no curated prompts needed” claim is an average-case result, not absolute.
What is the main weakness of SCOPE?
The authors name it directly: rubric generation quality. The frozen judge’s reward is only as reliable as the rubric it extracts from each document, so weak rubrics cap the whole co-evolution loop. It is also untested above 8B and confined to tasks answerable from a retrieval corpus.