AI Agents · Reinforcement Learning · Retrieval-Augmented Generation
Harness-1: Move Search-Agent Bookkeeping Out of the Policy
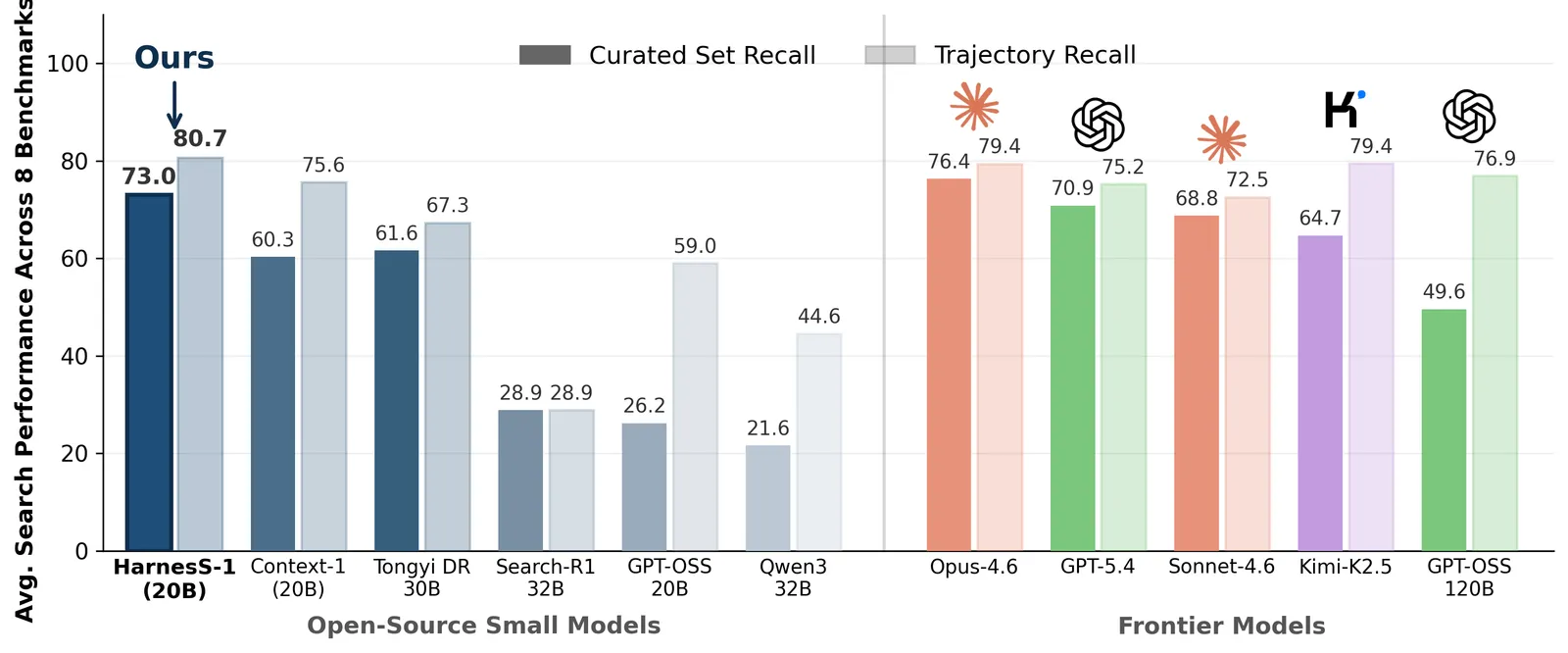
Harness-1 is a 20B RL search agent that hands working memory to the environment, hitting 0.730 average curated recall and beating the next open subagent by +11.4 points.
Quick answer
Harness-1 is a 20B retrieval subagent trained with reinforcement learning, but the headline idea is not the model size. It is what the model is not asked to do. The authors strip routine state management (tracking candidates, deduping evidence, recording what has been verified, deciding what fits in context) out of the policy and push it into the surrounding harness, the environment-side scaffolding the agent runs inside. The policy keeps only the semantic calls: what to search, what to keep, what to verify, when to stop.
The payoff is a measured one. Across eight retrieval benchmarks spanning web, finance, patents, and multi-hop QA, Harness-1 reaches 0.730 average curated recall, +11.4 points over the next strongest open search subagent, and stays competitive with much larger frontier-model searchers. The gains are largest on held-out transfer benchmarks, which is the result that matters most: it suggests the learned behavior is a generalizable search skill, not benchmark memorization.
What “state-externalizing harness” actually means
A typical search agent is trained as a policy over a growing transcript. Every turn, the same network has to do two jobs at once: make a genuinely hard semantic decision (which query, which document), and also remember the boring stuff: which constraints are still open, which claims it already checked, which of fifty retrieved passages are worth keeping. The paper’s argument is that RL is a wasteful tool for the boring stuff. Bookkeeping is recoverable. The environment can maintain it deterministically and reliably, so forcing gradient descent to relearn it from sparse reward just adds variance.
So Harness-1’s harness maintains environment-side working memory: a candidate pool, an importance-tagged curated set, compact evidence links, verification records, compressed and deduplicated observations, and budget-aware context rendering (what to actually show the model given a token budget). The model issues semantic actions; the harness updates the state and renders the next view. This is a clean separation-of-concerns move borrowed from systems design and applied to agent training.
How the RL training fits the split
Once bookkeeping lives in the environment, the reward can target the thing you care about: did the agent assemble the right evidence? The reported metric is curated recall (how much of the gold supporting evidence ends up in the agent’s curated set) rather than only final-answer accuracy. That is a deliberate choice. For a retrieval subagent whose output feeds a downstream reader or planner, recall of the right evidence is the honest objective; answer accuracy conflates retrieval quality with the reader’s reasoning.
Training a 20B model with RL on this signal, inside a stateful harness, is what produces the transfer behavior. The authors frame the generalization claim carefully. RL over explicit search state can yield retrieval policies that hold up outside the training domains, which is the opposite of the usual worry that RL agents overfit their training environment.
Why this lands now
Search and “deep research” agents are the loudest agent category of 2026, and most published systems chase end-to-end answer accuracy with ever-larger policies. Harness-1 is a useful counterweight: a 20B model that is competitive with frontier-scale searchers because it spends its parameters on judgment instead of memory. If the result holds, the practical lesson for anyone building retrieval agents is to audit how much of your policy’s burden is recoverable state, then move it out.
Key results
- 0.730 average curated recall across eight retrieval benchmarks (web, finance, patents, multi-hop QA).
- +11.4 points over the next strongest open search subagent, the central comparison.
- Competitive with much larger frontier-model searchers at only 20B parameters, the size-efficiency claim.
- Largest gains on held-out transfer benchmarks, the evidence that the harness teaches a generalizable search skill rather than a benchmark-specific trick.
- Metric of record is curated recall (did the right evidence land in the curated set), not just final-answer accuracy, which is the right call for a retrieval subagent.
Limits and open questions
The honest caveats are about scope and reporting. First, curated recall is a retrieval-side metric: it measures whether good evidence was gathered, not whether a downstream model then answers correctly. A high-recall subagent can still feed a weak reader, so end-to-end gains are not guaranteed by these numbers alone. Second, “competitive with much larger searchers” is a soft claim. The abstract does not pin which frontier models or by what margin, so treat parity as directional until the per-benchmark tables are read in full. Third, the harness itself is hand-engineered: candidate pools, importance tags, dedup, and budget rendering are design decisions, and the paper’s gains may partly reflect a well-tuned scaffold rather than the RL alone. An ablation isolating harness-vs-policy contribution is what a skeptical reader should look for. Finally, building and maintaining a stateful harness is real engineering overhead that a plain transcript policy avoids.
Who should skip it: if you only need a one-shot RAG retriever for a single domain, the harness machinery is overkill. The payoff shows up in multi-hop, multi-constraint, transfer-heavy search.
FAQ
What makes Harness-1 different from a normal RL search agent?
Normal search agents fold both semantic decisions and routine bookkeeping into one policy. Harness-1 externalizes the bookkeeping (candidate pool, dedup, verification records, budget-aware context) into the environment-side harness, so RL only optimizes the semantic decisions: what to search, keep, verify, and when to stop.
How good is Harness-1’s 0.730 curated recall in context?
It is the average across eight retrieval benchmarks and beats the next strongest open search subagent by +11.4 points, while staying competitive with much larger frontier-model searchers despite being only 20B parameters. The strongest gains appear on held-out transfer benchmarks.
Should I use Harness-1 if I already have a RAG pipeline?
Only if your task is hard search: multi-hop, multi-constraint, or cross-domain. For single-domain one-shot retrieval the stateful harness is more engineering than you need; its advantage is in transfer and in assembling curated evidence across many steps.