AI Agents · Code Generation · Retrieval-Augmented Generation
SWE-Explore: Can Coding Agents Find the Right Code?
SWE-Explore isolates the repo-exploration stage of coding agents over 848 issues. Agentic explorers crush BM25 (HitFile 0.65 vs 0.08), but line-level recall stalls at 0.15-0.20, and that gap is what limits repairs.
Quick answer
SWE-Explore is a benchmark that scores only one thing: how well a coding agent finds and ranks the code it needs before it tries to patch a bug. It strips away the actual editing step, so a model that writes great diffs but searches blindly can no longer hide behind a lucky fix.
The headline split is stark. On HitFile (did the agent touch the right files?), agentic explorers built on modern LLMs land around 0.65, while classical retrieval like BM25 sits at 0.079 and TF-IDF at 0.140. So the “just embed the repo and retrieve” era is genuinely over for this task. But the same agents that nail files only recover 0.15-0.20 of the relevant lines. That recall ceiling, not file-finding, is what holds back end-to-end repair.
Inside the benchmark
SWE-Explore covers 848 issues across 203 open-source repositories and 10 programming languages. It is not Python-only: Python is 64.5%, then Go (9.9%), JavaScript (6.0%), Rust (3.7%), Java (3.5%), and five more. The repos are large and realistic, averaging 759 files and roughly 180K lines of non-test source. Each instance ships with ground truth averaging 4.3 files, 4.7 code regions, and 1,578 visible lines.
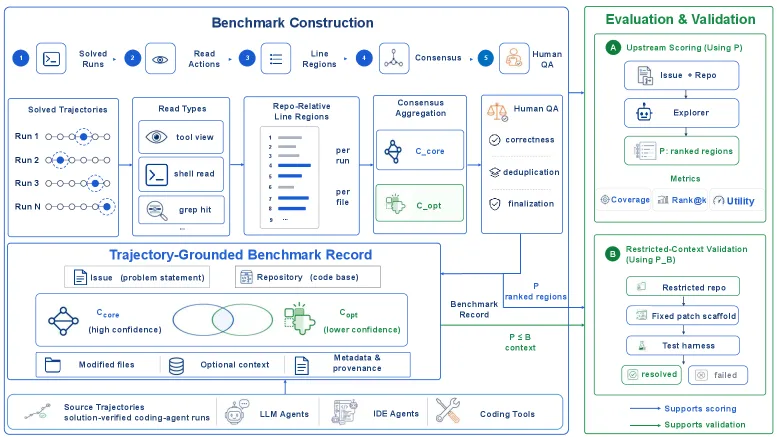
The clever part is where ground truth comes from. Instead of asking humans to guess what context “should” matter, the authors mine trajectories from agents that actually resolved each issue. An instance is kept only if at least two successful resolution trajectories exist; the useful regions are taken as the intersection of those trajectories, then cleaned with an LLM pass and a human audit. So “relevant code” means “code that real successful fixes touched,” not an annotator’s intuition.
How the scoring works
An explorer is asked to return a ranked list of relevant code regions under a fixed budget, with K=5 regions per query (matching the 4.7-region average). SWE-Explore then grades on four axes:
- Coverage and accuracy: line-level Precision, Recall, F1, plus HitFile and HitRegion.
- Ranking: nDCG@500, with line budgets so verbose dumps do not win for free.
- Ranking under budget: First Useful Hit (FUH) and budgeted prefixes at 100, 300, and 500 lines.
- Efficiency and noise: Context Efficiency (useful coverage divided by emitted context) and noise rates.
These are not arbitrary. The paper shows each correlates tightly with whether the downstream repair actually succeeds: Context Efficiency reaches Pearson r = +0.950, First Useful Hit +0.928, HitFile +0.925, and nDCG@500 +0.921. That is the benchmark’s strongest claim. Exploration quality is a genuine predictor of fix quality, so optimizing it is not busywork.
Key results
Three findings cut against the usual “bigger model wins” reflex.
First, the bottleneck is missing evidence, not clutter. When the authors removed half the ground-truth regions, resolve rates dropped sharply. Adding non-core regions barely hurt once enough real evidence was present. Agents fail by not finding the key code, not by drowning in noise. That reframes a lot of context-window anxiety.
Second, specialized exploration beats general scale. CoSIL, which does iterative code-graph search, hit line recall of 0.788 versus 0.15-0.19 for general coding agents, a 4x gap. The mechanism (how you walk the repo graph) mattered far more than which frontier LLM sat behind it.
Third, the model only shifts the operating point, not the wall. Across a Mini-SWE-Agent scaffold, GPT-5.4 posted the strongest metrics, but line-level recall stayed limited for every model tested. The paper’s own phrasing is the honest summary: “LLM choice shifts the operating point, but not the bottleneck.”
Limits and open questions
Read the numbers with three caveats. The benchmark only contains issues that at least one agent in the test pool could already solve, so it cannot measure exploration on problems nobody has cracked. Survivorship is baked in. The trajectory-derived ground truth approximates useful context, not strictly necessary context, so line-recall scores have a soft ceiling that may understate good-but-different searches. The restricted-context protocol the authors use to validate correlations is a measurement tool, not a literal patch-generation pipeline.
The open question is whether the line-recall wall is a retrieval problem or a reasoning one. CoSIL’s code-graph win suggests better structural search helps, but nobody has shown an explorer that reaches both 0.65 HitFile and high line recall at once. Whoever closes that gap probably moves SWE-bench-style scores too.
FAQ
What does SWE-Explore measure that SWE-bench does not?
SWE-bench grades the final patch: did the tests pass. SWE-Explore grades the step before. Given an issue and a big repo, can the agent locate and rank the relevant code regions within a line budget? It isolates exploration so you can tell a good searcher from a lucky patcher, and shows those exploration metrics predict repair success with Pearson r above 0.92.
Do retrieval methods like BM25 still work for coding agents?
Not competitively. On SWE-Explore, BM25 scores 0.079 HitFile and 0.021 line recall, and TF-IDF 0.140 HitFile, far below agentic explorers near 0.65 HitFile. Classical retrieval forms a clearly lower tier, so for repository-scale localization the agentic, tool-using approach has won decisively.
Why are coding agents still bad at line-level localization in SWE-Explore?
Because finding the right file is now easy (HitFile around 0.65) but recovering the right lines is not. Line recall stalls at 0.15-0.20 for general agents. The paper shows low F1 is mostly a recall problem, and that missing core evidence, not redundant context, is the dominant failure mode driving repair failures.