Video Generation · Diffusion Models
SCAIL-2: End-to-end In-Context Conditioning for Character Animation
SCAIL-2 feeds the raw driving video into the generation sequence instead of a pose skeleton, cutting FVD to 287 vs 305 for Wan-Animate on Studio-Bench, with one model covering animation and replacement.
Quick answer
SCAIL-2 transfers motion by concatenating the raw driving video into the generation sequence, so the model reads the full driving frames instead of a pose skeleton or a masked background. On Studio-Bench pose-driven evaluation it reaches FVD 287.11 and SSIM 0.6453 when paired with a SAM3D-Body mesh, against Wan-Animate at 305.31 / 0.6340 and VACE at 387.52 / 0.5942. The gain comes from the end-to-end driving design and a synthetic data pipeline, not a new backbone: the model is a full fine-tune of Wan2.1-14B-I2V. One model handles single-character animation, zero-shot multi-character, and character replacement.
The intermediate-representation problem
Pose-driven animators convert the driving video into a skeleton or a masked background, then generate from that. Anything the skeleton cannot encode is gone before generation starts: hand-object contact, fine clothing, how two characters physically interact. The paper argues this lossy bottleneck is what caps prior methods on complex motion.
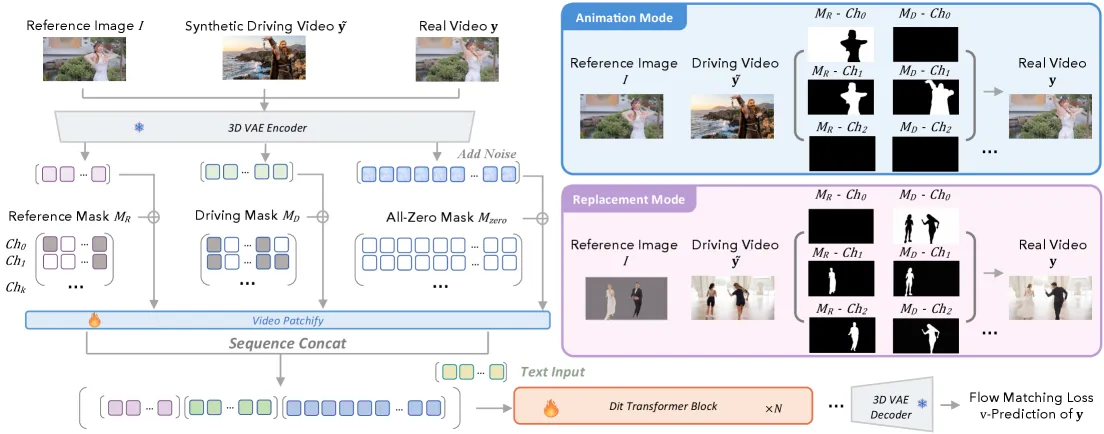
SCAIL-2 removes the intermediate. The I2V backbone receives [z_ref; z_t; z_driv], the concatenation of reference tokens, noisy video tokens, and driving tokens, with the driving tokens shifted by a fixed spatial offset so they stay detached from the output frames. The driving video is the condition, raw, so the model can pull motion, interaction, and scene detail directly from pixels.
How one model covers many tasks
End-to-end conditioning alone does not tell the model whether to keep the reference background (animation) or the driving background (replacement), or which character a motion belongs to. SCAIL-2 adds an in-context mask with extra channels stacked onto the input. One environment-switch channel flags whether the background comes from the reference image or the driving video. Six binding-slot channels (K=6, 28 added channels total) say that motion flows only within characters sharing a slot, which is how it isolates identities in multi-character scenes and supports more than six characters by letting distant ones share a slot. Mode-specific RoPE disambiguates animation versus replacement layout.
The training masks are derived only from reference images and driving sequences, never from ground truth; the denoising latents carry an all-zero mask. The paper calls this the core difference from prior conditioning schemes.
The data pipeline does the heavy lifting
End-to-end supervision needs paired data that mostly does not exist, so SCAIL-2 synthesizes it. An agentic loop (Candidate Selector, Prompt Weaver, Quality Checker, plus a strong multi-reference image generator) builds plausible reference images from human-centric datasets, then a pose-driven generator animates them into pairs. The result is MotionPair-60K: about 31,895 SCAIL single-animation pairs, 13,847 from Wan-Animate, 9,249 single and 4,385 multi replacement pairs from MoCha, and roughly 100,000 pose-extraction pairs, sampled 60/20/20.
Because real videos act as supervision, the model is steered to compose abilities and can surpass the generators that made its training data. That is the load-bearing claim: the gain is the end-to-end paradigm plus reverse-driving data, not the underlying generators.
Bias-Aware DPO
Synthetic pairs carry artifacts in detailed regions. SCAIL-2 runs a post-training stage of 400 DPO steps with a mask-weighted preference loss (Bias-Aware DPO) that focuses the preference signal on biased regions, combined with an SFT term on the positive sample. It targets fidelity in fine areas the synthetic data gets wrong.
Key results
- Studio-Bench pose-driven (Table 2): SCAIL-2 + SAM3D-Body mesh hits SSIM 0.6453 / PSNR 19.09 / LPIPS 0.2231 / FVD 287.11, beating Wan-Animate (0.6340 / 305.31) and clearly beating VACE (0.5942 / 387.52) and UniAnimate-DiT (0.6367 / 480.15 FVD).
- Mesh beats skeleton, zero-shot: swapping the NLF-Pose skeleton for a SAM3D-Body mesh lifts SSIM from 0.6370 to 0.6453, even though the model never saw mesh input in training, evidence that a richer condition feeds more usable information.
- Video-Bench (Table 3): Imaging Quality 4.43 (best, vs SteadyDancer 4.41), Appearance Consistency 4.38 (best), Temporal Consistency 4.18.
- Human evaluation (GSB): wins all metrics over open-source baselines on single-character animation and stays close to proprietary Kling 3.0; multi-character results are zero-shot and lead on identity isolation.
- Ablation (Table, Video-Bench): full model 4.63 Imaging Quality vs 4.47 without Binding Slots and 3.90 without the replacement task, so the binding mask and task unification both contribute.
Read these as cross-identity animation gains over open-source baselines like Wan-Animate, SteadyDancer, and VACE, with proprietary Kling 3.0 as the harder reference the model only approaches.
What the numbers do not prove
The headline FVD gain depends on pairing the model with a SAM3D-Body mesh; as a pure skeleton-driven generator the SSIM/PSNR are described as mediocre, so part of the win rides on a stronger driving representation rather than the model alone. The multi-character lead is zero-shot, which is impressive but means it rests on the data construction holding up under inputs the model never trained on. Bias-Aware DPO is acknowledged to struggle to find reliable positive samples in fine-grained regions, so fidelity in faces and small details is still open. And the whole approach depends on synthetic data whose ceiling is set by the generators that made it.
Builder judgment
If you run a pose-driven animation pipeline and lose information at the skeleton step, the reproducible idea here is concatenating raw driving video plus an in-context mask, not a new architecture; it fits an existing I2V backbone. The cost is real: a full fine-tune of a 14B model on 64 H100s for about a week, plus building a synthetic-pair pipeline before any training. Teams without that data engine get the least, because the binding slots and replacement mode only work once the curated pairs exist. The honest watch item is fine-region fidelity, which the paper leaves to future work.
Limits and open questions
SCAIL-2 reports no training-cost comparison against the baselines beyond its own 64-H100-week figure, so the efficiency tradeoff against pose-driven methods is unstated. External validity leans on Studio-Bench, X-Dance, and a new replacement benchmark the authors built themselves, and the strongest pose-driven numbers require an external mesh extractor in the loop. The synthetic-data dependency is the structural limit: fidelity is capped by the generators, reliable positive samples for fine regions are hard to get, and tasks like lip-sync and facial expression are named as not yet handled. A subset of data and the weights are promised on the project page, so reproducibility hinges on that release.
FAQ
What is SCAIL-2?
SCAIL-2 is an end-to-end controlled character animation framework from Zhipu AI and Tsinghua that concatenates the raw driving video into the generation sequence instead of converting it to a pose skeleton or masked background. It reaches FVD 287.11 on Studio-Bench versus 305.31 for Wan-Animate and runs on a fine-tuned Wan2.1-14B-I2V backbone.
How is SCAIL-2 different from pose-skeleton animators like Wan-Animate?
Pose-driven methods turn the driving video into a skeleton, dropping hand-object contact and interaction detail before generation. SCAIL-2 feeds the raw driving frames in-context, so the model reads that information directly, which is why a mesh-based driving signal lifts its SSIM to 0.6453 zero-shot.
What is MotionPair-60K and why does SCAIL-2 need it?
MotionPair-60K is the synthetic paired dataset SCAIL-2 builds with an agentic editing loop: about 31,895 SCAIL animation pairs, 13,847 from Wan-Animate, 13,634 replacement pairs from MoCha, and roughly 100,000 pose pairs. End-to-end supervision needs paired motion data that does not exist naturally, so the pipeline synthesizes it.
Does SCAIL-2 handle multi-character animation and replacement?
Yes. Binding-slot mask channels (K=6) tie motion to specific characters, giving zero-shot multi-character animation with strong identity isolation, and an environment-switch channel lets the same model do character replacement, beating Wan-Animate and the MoCha generator that produced its replacement training pairs.
One line: SCAIL-2 drops the pose-skeleton bottleneck by driving generation with the raw video plus an in-context mask, buying lower FVD and one unified model at the cost of a heavy synthetic-data pipeline. Read the original paper on arXiv.