SWE-Explore:编程智能体真能找对代码吗
SWE-Explore 单独考核代码探索:848 个 issue 上智能体远超 BM25(HitFile 0.65 对 0.08),但行级召回卡在 0.15-0.20,这才是真瓶颈。
快速答案
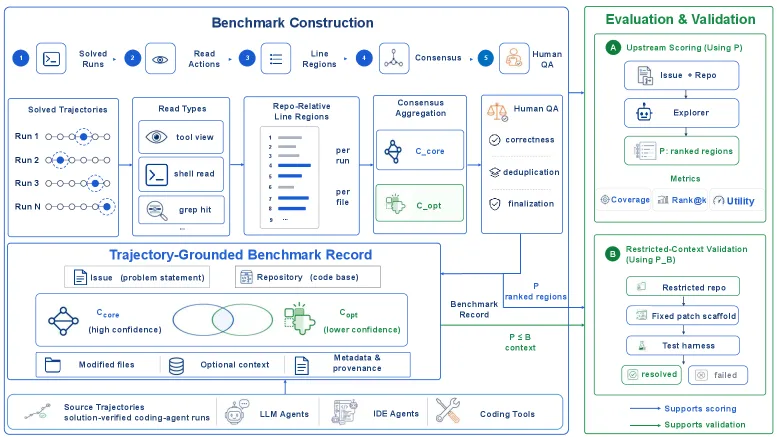
SWE-Explore 只考核一件事:编程智能体在动手改 bug 之前,能不能找到并排好它真正需要的代码。它把实际改代码那一步剥离掉,于是一个”补丁写得好但搜索全靠蒙”的模型,再也没法用一次侥幸的修复糊弄过去。
最显眼的结论很扎眼。在 HitFile 这个指标(智能体改对文件了吗)上,基于现代大模型的智能体探索器约 0.65,而经典检索 BM25 只有 0.079、TF-IDF 只有 0.140。所以在这个任务上,“把仓库嵌入向量再检索”的时代是真的过去了。但同一批能精准找到文件的智能体,对相关代码行的召回只有 0.15-0.20。拖住端到端修复后腿的,正是这道行级召回的天花板,而不是找文件。
基准长什么样
SWE-Explore 覆盖 848 个 issue、203 个开源仓库、10 种编程语言。它不是只盯 Python:Python 占 64.5%,其后是 Go(9.9%)、JavaScript(6.0%)、Rust(3.7%)、Java(3.5%),还有另外五种。仓库都是真实的大工程,平均 759 个文件、约 18 万行非测试源码。每个实例自带的标准答案平均涉及 4.3 个文件、4.7 个代码区域、1578 行可见代码。
最巧的是标准答案怎么来的。作者没有让标注员去猜”哪些上下文该重要”,而是从真正成功修复了该 issue 的智能体轨迹里挖。一个实例只有在至少存在两条成功修复轨迹时才保留;有用区域取这些轨迹的交集,再经一遍大模型清洗加人工审核。所以”相关代码”的定义是”真实成功修复所触碰过的代码”,而非标注员的直觉。
打分机制怎么设计
探索器被要求在固定预算下返回一个排好序的相关代码区域列表,每次查询 K=5 个区域(对应 4.7 区域的平均值)。SWE-Explore 从四个维度打分:
- 覆盖与准确:行级 Precision、Recall、F1,外加 HitFile 与 HitRegion。
- 排序:nDCG@500,并带行数预算,让”无脑堆代码”占不到便宜。
- 预算下的排序:First Useful Hit(FUH)与 100、300、500 行的截断前缀。
- 效率与噪声:Context Efficiency(有用覆盖除以输出上下文长度)与噪声率。
这些指标并非随手定。论文证明每一个都与下游修复是否成功高度相关:Context Efficiency 的皮尔逊相关 r 达 +0.950,First Useful Hit +0.928,HitFile +0.925,nDCG@500 +0.921。这是该基准最硬的一条主张:探索质量确实能预测修复质量,所以为它做优化绝不是白费功夫。
关键结果
有三条发现,都跟”模型越大越赢”的本能反应相反。
第一,瓶颈是证据缺失,不是信息冗余。作者把一半标准答案区域删掉后,修复率骤降;而只要核心证据足够,再加入非核心区域几乎不掉分。智能体的失败来自没找到关键代码,而不是被噪声淹没。这把很多关于上下文窗口的焦虑重新框定了一遍。
第二,专用探索机制胜过通用大模型。做迭代式代码图搜索的 CoSIL,行级召回达到 0.788,而通用编程智能体只有 0.15-0.19,差了 4 倍。决定胜负的是机制(你怎么在仓库图上走),远胜于背后挂的是哪个前沿大模型。
第三,换模型只挪动工作点,撞不破那堵墙。在 Mini-SWE-Agent 框架下,GPT-5.4 各项指标最强,但所有被测模型的行级召回都受限。论文自己的话最诚实:“模型选择改变的是工作点,而非瓶颈”。
局限与存疑
读这些数字时要带三点保留。其一,基准里只收录了测试池中至少有一个智能体已经能解的 issue,所以它无法衡量”没人解出来过的难题”上的探索能力,幸存者偏差是内建的。其二,从轨迹推导出的标准答案近似的是有用上下文,而非严格必要的上下文,因此行级召回分有一个软上限,可能低估了”路子不同但也对”的搜索。其三,作者用来验证相关性的受限上下文协议,是一种度量工具,而不是字面意义上的补丁生成流水线。
留下的开放问题是:行级召回这堵墙,到底是检索问题还是推理问题?CoSIL 靠代码图搜索取胜,提示更好的结构化搜索有用,但还没人做出一个同时达到 0.65 HitFile 和高行级召回的探索器。谁补上这道缺口,多半也能把 SWE-bench 那类分数一起拉高。
常见问题
SWE-Explore 比 SWE-bench 多考核了什么?
SWE-bench 评的是最终补丁,即测试过没过。SWE-Explore 评的是前一步:给定一个 issue 和一个大仓库,智能体能否在行数预算内定位并排好相关代码区域。它把探索环节单独抽出来,让你能区分”真会搜的”和”运气好碰对的”,并证明这些探索指标对修复成功的预测皮尔逊相关 r 超过 0.92。
BM25 这类检索方法对编程智能体还管用吗?
已经没有竞争力。在 SWE-Explore 上,BM25 的 HitFile 只有 0.079、行级召回 0.021,TF-IDF 的 HitFile 是 0.140,远低于智能体探索器约 0.65 的 HitFile。经典检索明显落在更低的一档,所以在仓库级定位上,会用工具的智能体路线已经完胜。
为什么编程智能体在 SWE-Explore 里行级定位还是很差?
因为找对文件现在已经很容易(HitFile 约 0.65),但找回正确的代码行不容易。通用智能体的行级召回卡在 0.15-0.20。论文指出,低 F1 主要是召回问题,而缺失核心证据(不是上下文冗余)才是驱动修复失败的主导失效模式。