APPO:智能体过程化策略优化详解
APPO 把 RL 分叉点放在高不确定且高影响的 token 上,而非工具调用边界,在 13 个基准上让 Qwen2.5-7B 比 ARPO 高 3.9 分。
快速答案
APPO 是一种智能体强化学习训练方法,把信用分配的力气花在真正决定结果的 token 上,而不是工具调用边界。在 Qwen2.5-7B-Instruct 上,它在 13 个基准的平均分是 62.2,ARPO 是 58.3,高 3.9 分;Llama3.1-8B 上是 57.4 对 55.3。提升来自训练配方,不是更强的底座:微调的是同一批 checkpoint,所以任何收益都属于 RL 过程和 rollout 树,而非新的预训练。
APPO 要解决的信用分配难题
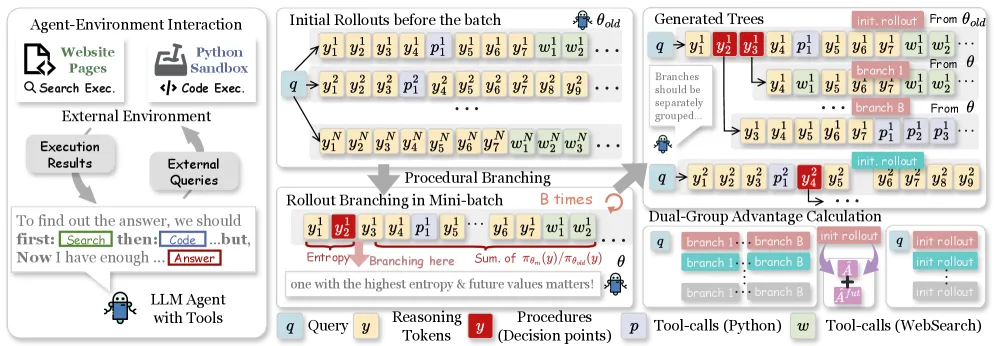
智能体 RL 通常只用一个结果信号给整条轨迹打分,之后就很难说清是哪一步中间决策赢得了奖励。ARPO 这类方法用工具调用边界等启发式单元来分叉 rollout。论文图 1 的分析认为这个锚点选错了:高熵 token 并不聚集在工具调用处,而且单看熵也不可靠,因为有些熵峰只是生僻词(比如 march、november),不是任务关键的分叉点。
这个观察决定了整套设计。如果你在模型只是对用词犹豫的地方分叉,就把 rollout 预算浪费在了噪声上。APPO 只在不确定性和下游影响同时出现时才分叉。
分叉打分怎么算
APPO 用两个归一化信号的乘积给每个 token 打分(公式 5)。一个是 token 熵,代表模型的局部不确定性。另一个是累积、带折扣的重要性采样比,用来估计这个 token 之后的续写在当前策略下变化多大,相当于度量这个选择改变了多少未来。两者在一条 rollout 内做 z-score 归一化再相乘,所以只有既不确定又有后果的 token 才会得高分。
rollout 循环像一棵树:先生成 N 条完整 rollout,在每条里按分叉分数取 top-B 个 token,从这些点重采续写,直到用完预算 M。论文给出的最佳配置是 M=16 时 N=4、B=3;均衡设置胜过极端设置,说明方法靠的是把预算铺开,而非到处分叉。
过程级优势缩放
第二部分是怎么把奖励转成逐 token 的信用。APPO 把初始 rollout 和分叉续写分到不同的优势组(dual-group),避免混合来自不同采样条件的分布。再加一个未来感知优势项,同样由折扣似然比构成,乘进基础优势里,让下游影响更强的 token 拿到更大信用。目的是把奖励推到真正起作用的稀疏分叉上,而不是均摊到整条轨迹。
关键结果
- Qwen2.5-7B-Instruct,13 基准平均: APPO 62.2 对 ARPO 58.3(+3.9)。AIME24 从 30.0 升到 36.7。
- Llama3.1-8B-Instruct,13 基准平均: APPO 57.4 对 ARPO 55.3(+2.1)。AIME24 从 23.3 到 30.0。
- 深度搜索(GAIA): Qwen3-8B 42.7 对 38.8(+3.9);Qwen3-14B 46.6 对 43.7(+2.9)。
- 基准构成: 5 个数学(AIME24、AIME25、MATH500、GSM8K、MATH),5 个知识密集多跳(WebWalker、HotpotQA、2WikiMultihopQA、Musique、Bamboogle),3 个深度搜索(GAIA、Humanity’s Last Exam、Xbench)。
- 消融(Qwen2.5-7B,5 个知识任务): 去掉未来感知优势项掉 3.4 分,去掉 dual-group 掉 2.1 分,把完整分叉分数换成只用熵掉 1.8 分。未来项是最大的杠杆。
这些数字应读作:相对同等 RL 基线的智能体 RL 训练收益。对比集既有经典 RL 配方(GRPO、Reinforce++、DAPO、GPPO、CISPO),也有智能体 RL(GIGPO、ARPO),所以结论是更好的 RL 过程,参照物是 ARPO,而非一个没训过的底座。
这些数字没有证明什么
3.9 分的平均提升是在已经 RL 调过的智能体之上做几个百分点的配方改进,不是底座能力的跃升。dual-group 和未来感知项都绑在 APPO 自己的树状 rollout 上,所以收益不能当成一个 loss 直接搬到任意轨迹数据集,你还得带上那套分叉机制。Pass@K 曲线随 k 增大而拉开,说明 APPO 主要重塑候选轨迹的分布,而不是稳定产出单个更好的答案,所以单样本部署看到的效果可能比平均值小。
对开发者的判断
如果你已经在跑带工具调用的智能体 RL,而且分叉锚在工具边界上,APPO 值得复现,最便宜的部分是采用它选探索位置的分叉打分准则。没有 RL 训练栈的团队基本用不上,这是训练期方法,不是推理技巧。需要盯的是成本:分叉加上累积重要性比的计算会带来开销,论文没用工具调用数或 token 数量化,只说工具调用数差不多,没给硬指标。
局限与存疑
论文没有给分叉树的明确算力、墙钟或 token 成本核算,所以效率说法只靠工具调用数差不多,没有实测预算。外部有效性是常见保留:结果只在 Llama3.1-8B、Qwen2.5-7B、Qwen3-8B/14B 和特定基准切分上,而深度搜索数字靠 GAIA,小幅绝对提升可能有噪声。复现取决于分叉预算、打分超参和奖励设置是否公开到足以重建那棵树,因为没有它优势缩放就没意义。
常见问题
APPO(智能体过程化策略优化)是什么?
APPO 是面向 LLM 智能体的 RL 微调方法,用熵和折扣重要性采样比的组合来选分叉点,再用过程级优势缩放让高影响 token 拿更多信用。Qwen2.5-7B 上 13 基准平均 62.2,ARPO 是 58.3。
APPO 和 ARPO、工具边界分叉有什么区别?
ARPO 在工具调用边界等启发式单元上分叉。APPO 认为高熵、决定性的 token 并不聚集在工具调用处,所以它在既不确定又有下游影响的 token 上分叉,这正是 Qwen2.5-7B 比 ARPO 高 3.9 分的来源。
APPO 提升的是底座模型还是 RL 训练?
只是 RL 训练。微调用的是同一批底座 checkpoint(Llama3.1-8B、Qwen2.5-7B、Qwen3-8B/14B),所以 2.1 到 3.9 分的收益归功于 rollout 树过程和优势缩放,不是更好的预训练或更大的模型。
APPO 消融里哪个组件最关键?
未来感知优势项。在 Qwen2.5-7B 知识任务上去掉它掉 3.4 分,比去掉 dual-group(2.1)或把分叉分数降为只用熵(1.8)都多。
一句话:APPO 是智能体 RL 的信用分配配方,在决策要紧处而非工具调用处分叉,以论文没完全核算的 rollout 开销换来比 ARPO 高几分的结果。阅读 arXiv 原文。