DVAO:按方差自适应加权的多奖励强化学习
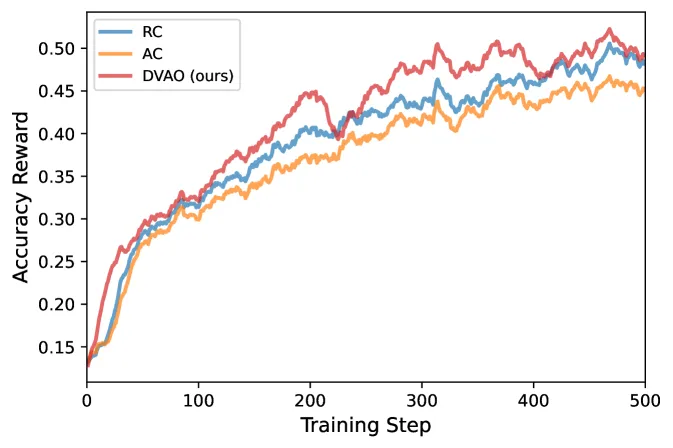
DVAO 按各奖励在组内的方差自适应加权,而非固定系数,在 Qwen3-4B-Base 上把平均准确率从 38.99% 提到 42.19%,长度合规率从 96.39% 拉到 99.91%。
快速答案
DVAO 是一种在 GRPO 式 LLM 强化学习里融合多个奖励信号的方法:它按每个目标在一组 rollout 内的经验奖励方差的倒数来加权该目标的优势,而不是用人工调出来的固定系数。在 Qwen3-4B-Base、各目标等权设置下,DVAO 平均准确率达 42.19%,高于奖励组合的 38.99% 和优势组合的 38.75%,同时把长度合规率推到 99.91%(原本约 96%)。重点不在准确率涨了多少,而在于准确率和次要约束能同时拿到,且训练不崩。
GRPO 里的多奖励难题
多数 LLM 强化学习只优化一个奖励(答案对不对)。真实落地往往要同时满足好几个:答对、格式规范、长度在预算内、工具调用合法。两种显而易见的融合方式各有各的死法。奖励组合先把奖励加起来,再算一个优势——但相加后的奖励可能产生很大的优势幅度,把策略梯度搞不稳。优势组合给每个目标单算优势再按固定权重相加——尺度稳了,但静态权重不知道一个「简单」目标(全组本来就格式正确)几乎没有学习信号,却还在持续淹没那个真正需要梯度的难目标。
DVAO 如何为目标加权
DVAO 的核心动作,是读取每个目标在一组 rollout 内的经验奖励方差,据此缩放该目标的优势。直觉很具体:如果采样的 16 条回答全都满足格式奖励,这个目标方差接近零,就该少贡献——这一组在它上面已经没什么可学的了。如果正确性奖励在组内差异很大,梯度信号就在那里,于是被上调权重。由于加权按组归一化,合并后的优势保持有界,这正是朴素奖励组合丢掉的稳定性。论文还加了一项自适应跨目标正则,防止一个目标把另一个压垮,同样由方差统计驱动,而非又一个要按任务重调的固定超参。
关键结果
以下数字均出自论文表格。组大小为每个 prompt 16 条 rollout,批大小 128,训练 500 步,使用 8 张 NVIDIA H20-3e。
- Qwen3-4B-Base,等权: DVAO 平均准确率 42.19%,领先奖励组合(38.99%)、优势组合(38.75%)和 GDPO(13.41%)。长度合规率达 99.91%,对比 96.39% / 96.23% / 97.81%。
- Qwen2.5-3B-Instruct: DVAO 平均准确率 56.66%、平均格式分 76.65%,对比奖励组合 51.02% / 60.48%、优势组合 53.47% / 64.69%、GDPO 52.73% / 65.88%。
- 基准横跨两域: 数学推理用 AIME-2024、AIME-2025、MATH500、OlympiadBench、AMC23;工具调用用 Berkeley Function Call Leaderboard(BFCL-v4)的 Live、Non-Live、Multi-Turn。
- 训练数据: 数学用 DAPO-MATH-17K(17,000 条 prompt),工具用 4,000 条 ToolRL 数据。
GDPO 在更难的 Qwen3-4B-Base 上崩到 13.41%,是最说明问题的一行:静态权重方法不只是表现差,在目标失衡时可能根本训不起来——而这恰是 DVAO 瞄准的场景。
为什么长度合规这个数字值得看
99.91% 的长度合规率,才是该抓眼球的结果,而不是约 3 个点的准确率提升。守住长度预算是次要目标的典型:固定权重要么忽略它(于是模型啰嗦),要么过度看重它(于是截断、丢准确率)。DVAO 在一次训练里同时拿到最高准确率和近乎满分的长度合规,正是方差自适应加权在做固定系数做不到的事——在相互拉扯的目标间取平衡,且不用按任务做调参扫描。
局限与存疑
绝对准确率的提升是温和的(几个点),对比集也窄——奖励组合、优势组合、GDPO,全是 GRPO 系的多奖励基线。论文没有对比通过搜索精调出来的固定权重方案,而那才是从业者真正会用的替代项,所以「免除调参负担」可信但未被直接度量。所有模型都是 3B–8B 区间的 Qwen3 与 Qwen2.5;方差信号在更大规模、或超过两三个目标时是否仍有信息量,这里没测。还有一个该警惕的已知失效模式:一个普遍很难的目标(每条 rollout 都失败)方差同样很低,可能在最该学它的时候被饿着。把它定位成轻量重加权小改动,8 张 H20 的算力开销也并不小。
常见问题
DVAO 和 GRPO 到底差在哪?
DVAO 保留了 GRPO 的组相对优势估计,但在涉及多个奖励时,按每个目标在组内经验奖励方差的倒数来加权该目标的优势,而不用固定系数。低方差目标(全组已解决)贡献小,高方差目标拿更多梯度。
DVAO 为什么不直接把奖励加起来?
先把奖励相加(奖励组合)会产生很大、无界的优势幅度,使训练不稳;在 Qwen3-4B-Base 上它只到 38.99% 准确率,而 DVAO 为 42.19%。DVAO 按组归一化让合并优势保持有界,这正是它要保住的稳定性。
DVAO 在哪些基准上有提升?
DVAO 在数学推理(AIME-2024、AIME-2025、MATH500、OlympiadBench、AMC23)和工具调用(BFCL-v4 Live、Non-Live、Multi-Turn)上测试,模型为 Qwen3-4B/8B-Base 与 Qwen2.5-3B/7B-Instruct,在平均准确率、格式与长度合规指标上领先。
DVAO 比精调的固定权重方案更值得用吗?
如果你有多个奖励又不想按任务扫权重,DVAO 的卖点是自动、由方差驱动的平衡且优势有界——Qwen3-4B-Base 上 99.91% 长度合规叠加最高准确率支持这一点。但论文没和穷尽调参的固定权重基线比,所以「无需调参」应视为有前景而非已证实。
一句话:按全组对一个奖励的分歧程度来给它加权,多奖励强化学习就能不靠按任务调参而保持稳定。阅读 arXiv 原文。