LLM Reasoning · Fine-Tuning & Adaptation · Language Models
DVAO: Variance-Adaptive Advantage Weighting for Multi-Reward RL
DVAO weights each reward by its in-group variance instead of fixed coefficients, lifting Qwen3-4B-Base from 38.99% to 42.19% average accuracy and length compliance to 99.91% in math-plus-tool-use RL.
Quick answer
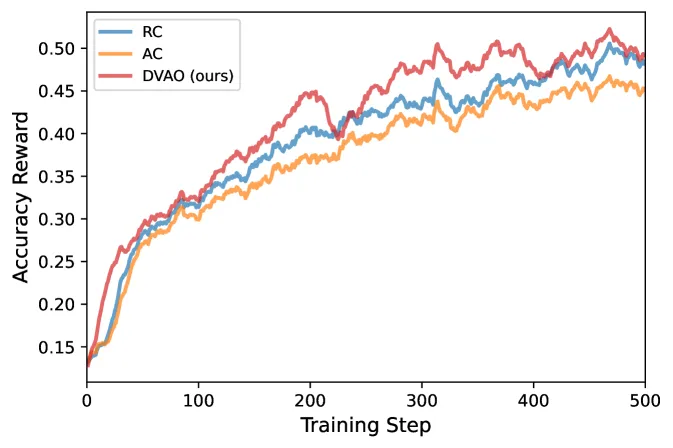
DVAO is a way to combine several reward signals in GRPO-style RL for LLMs by weighting each objective’s advantage by the inverse of its empirical reward variance inside a rollout group, rather than by hand-tuned coefficients. On Qwen3-4B-Base with equal target weights it reaches 42.19% average accuracy versus 38.99% for reward combination and 38.75% for advantage combination, while pushing length compliance to 99.91% (from ~96%). The point is not a huge accuracy jump — it is getting accuracy and a secondary constraint at the same time without the training blowing up.
The multi-reward problem in GRPO
Most RL-for-LLM work optimizes one reward (is the answer correct). Real deployments want several at once: correct and well-formatted and within a length budget and a valid tool call. The two obvious ways to merge them both fail in a specific manner. Reward combination sums the rewards first, then computes one advantage — but summed rewards can produce large advantage magnitudes that destabilize the policy gradient. Advantage combination computes a separate advantage per objective and adds them with fixed weights — stable in scale, but the static weights cannot know that an “easy” objective (everyone in the group already gets the format right) carries almost no learning signal, while it keeps drowning out the hard objective that actually needs gradient.
How DVAO weights objectives
DVAO’s core move is to read the empirical reward variance of each objective within a rollout group and scale that objective’s advantage accordingly. The intuition is concrete: if every one of the 16 sampled responses already satisfies the format reward, that objective’s variance is near zero and it should contribute little — the group has nothing left to learn there. If correctness reward varies widely across the group, that is where the gradient signal lives, so it gets up-weighted. Because the weighting is normalized per group, the combined advantage stays bounded, which is the stability property that plain reward combination loses. The paper adds a self-adaptive cross-objective regularization term so one objective cannot collapse another, again driven by the same variance statistics rather than a fixed hyperparameter you have to retune per task.
Key results
All numbers are from the paper’s tables. Group size is 16 rollouts per prompt, batch 128, 500 training steps, on 8x NVIDIA H20-3e GPUs.
- Qwen3-4B-Base, equal weights: DVAO hits 42.19% average accuracy, ahead of reward combination (38.99%), advantage combination (38.75%), and GDPO (13.41%). Length compliance reaches 99.91%, versus 96.39% / 96.23% / 97.81%.
- Qwen2.5-3B-Instruct: DVAO reaches 56.66% average accuracy and 76.65% average format score, versus 51.02% / 60.48% (reward combination), 53.47% / 64.69% (advantage combination), and 52.73% / 65.88% (GDPO).
- Benchmarks span both domains: math reasoning on AIME-2024, AIME-2025, MATH500, OlympiadBench, AMC23, plus tool use on Berkeley Function Call Leaderboard (BFCL-v4) Live, Non-Live, and Multi-Turn.
- Training data: DAPO-MATH-17K (17,000 prompts) for math and a 4,000-sample ToolRL set for tool use.
The GDPO collapse to 13.41% on the harder Qwen3-4B-Base setting is the most telling line: a static-weight method does not just underperform, it can fail to train at all when objectives are imbalanced, which is exactly the regime DVAO targets.
Why the length-compliance number matters
The 99.91% length compliance is the result that should catch your eye, not the ~3-point accuracy gain. Holding a length budget is a classic case of a secondary objective that fixed weighting either ignores (so models ramble) or over-weights (so they truncate and lose accuracy). DVAO getting both top accuracy and near-perfect length compliance in one run is the evidence that variance-adaptive weighting is doing something fixed coefficients cannot — balancing objectives that pull in different directions without a per-task tuning sweep.
Limits and open questions
The gains are modest in absolute accuracy (a few points) and the comparison set is narrow — reward combination, advantage combination, and GDPO, all GRPO-family multi-reward baselines. There is no comparison against a heavily hand-tuned weighting found by search, which is the real-world alternative practitioners use, so “removes the tuning burden” is plausible but not directly measured. All models are Qwen3 and Qwen2.5 in the 3B-8B range; whether the variance signal stays informative at larger scale or with more than two or three objectives is untested here. And variance-based weighting has a known failure mode the paper should be read carefully on: an objective that is uniformly hard (every rollout fails) also has low variance and could be starved exactly when it matters most. The 8x H20 setup is also a real compute footprint for what is framed as a lightweight reweighting tweak.
FAQ
What does DVAO actually do differently from GRPO?
DVAO keeps GRPO’s group-relative advantage estimation but, when several rewards are involved, weights each objective’s advantage by the inverse of its empirical reward variance within the rollout group instead of using fixed coefficients. Low-variance objectives (already solved by the group) contribute less; high-variance ones get more gradient.
Why not just add up the rewards in DVAO’s setting?
Summing rewards first (reward combination) produces large, unbounded advantage magnitudes that destabilize training; on Qwen3-4B-Base it reaches 38.99% accuracy versus DVAO’s 42.19%. DVAO’s per-group normalization keeps the combined advantage bounded, which is the stability it is designed to preserve.
What benchmarks did DVAO improve on?
DVAO was tested on math reasoning (AIME-2024, AIME-2025, MATH500, OlympiadBench, AMC23) and tool use (BFCL-v4 Live, Non-Live, Multi-Turn), using Qwen3-4B/8B-Base and Qwen2.5-3B/7B-Instruct. It led on average accuracy and on format and length-compliance metrics.
Is DVAO worth using over a tuned fixed-weight scheme?
If you have multiple rewards and do not want to sweep weights per task, DVAO’s appeal is automatic, variance-driven balancing with bounded advantages — and 99.91% length compliance alongside top accuracy on Qwen3-4B-Base supports that. The paper does not benchmark it against an exhaustively tuned fixed-weight baseline, so treat the “no tuning needed” claim as promising rather than proven.
One line: weight each reward by how much the group disagrees about it, and multi-reward RL stays stable without per-task tuning. Read the original paper on arXiv.