Lip Forcing:实时口型同步的少步自回归扩散
首个自回归扩散口型同步法:把 14B 双向教师蒸馏成因果学生,每块只跑 2 步去噪,1.3B 跑到 31.58 FPS,首帧延迟亚毫秒。
快速答案
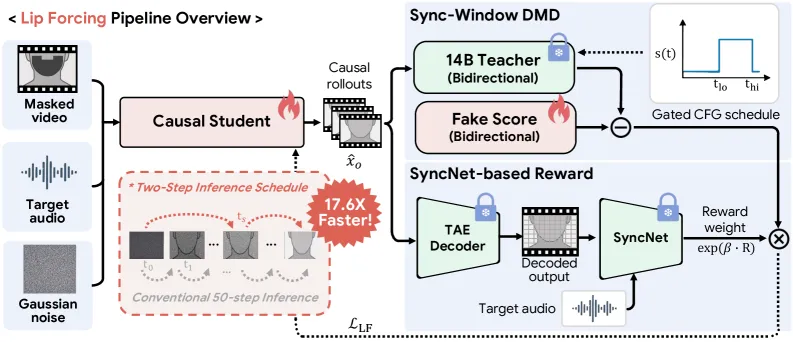
Lip Forcing 让扩散口型同步跑进实时,办法是把慢速的双向视频扩散模型改成逐块生成的因果模型。它的 1.3B 学生在 HDTF 上跑 31.58 FPS,首帧延迟 0.32ms,每块只用两步去噪,推理时不开 classifier-free guidance(CFG)。这比它蒸馏自的同规模双向模型快 17.6 倍;14B 学生比教师快 39.8 倍,比 LatentSync 快 4.7 倍。代价在同步质量:1.3B 的 Sync-C 只有 6.88,而 LatentSync 是 8.10,真值是 7.95,等于用一部分口型对齐换流式速度。
速度解决了什么问题
多数强口型扩散模型要先双向处理整段视频才吐第一帧。对齐好,但延迟糟:论文自己的表里,OmniAvatar-LS(14B)只有 0.38 FPS、首帧 213.72ms,LatentSync 是 3.23 FPS,都驱动不了实时数字人。Lip Forcing 借用了 Causal Forcing 这类少步视频模型在文生视频上用的自回归蒸馏配方,把它搬到视频转视频的口型同步:模型用已生成的帧加音频来条件化下一块,于是能边算边流式输出,不必等整段算完。
蒸馏怎么做
教师是一个 14B、音频条件的双向视频扩散模型。Lip Forcing 用分布匹配蒸馏(DMD,和 AnyFlow 这类少步生成器同一套路)加一个 fake-score 评论器把它蒸成因果学生。让 2 步版本真能用的有三件:
- 两步推理调度。 学生只在两个 ODE 索引 (0, 30) 上去噪。落点选在第 30 步是从 Euler 步分析推出来的:它在保留参考身份和让嘴跟上音频之间取了平衡。一步学生明显不如 50 步,所以他们保留第二步,而不是做成一步出图。
- Sync-Window DMD。 教师不再用固定 CFG 系数,而是只在 ODE 的 20-40 步内开 4.5 的引导,其余步用 1.0(不引导)。20-40 这一段正是轨迹分析发现生成对音频最敏感的区间。
- SyncNet 奖励。 用一个逐样本的乘性权重
w = exp(beta * R)(beta=2),按生成嘴形和条件音频之间的 SyncNet 置信度去缩放 DMD 梯度,同步好的样本训练时拉得更狠。梯度只走 DMD 损失,不回传过奖励函数。
CFG 保真度与同步度的权衡
不那么直观的发现是:这里的 CFG 没有一个两全的设置。把 CFG 调高(系数 4.5)能拉高 Sync-C,即口型对音频,但会损害参考保真度:生成的脸偏离原身份,嘴部更糙(LPIPS 更高)。关掉 CFG(系数 1.0)脸保真了,同步却松了。作者试过的固定系数没有一个两项都赢。他们的解法是不再把 CFG 当全局旋钮,而是按去噪步去开关:前段关掉护住身份,中段在最划算的区间开,之后再关。这个按步加窗的视角是核心思路,也是学生在把行为烤进蒸馏权重后能彻底丢掉推理期 CFG 的原因。
关键结果
均为 33 段 HDTF 测试集。真值参考:Sync-C 7.95,Sync-D 6.92。
- 1.3B 学生: 31.58 FPS,首帧 0.32ms,Sync-C 6.88,Sync-D 7.93,FVD 118.86,FID 6.76。实时,也是 FID-吞吐的最佳帕累托点,但 Sync-C 落后双向基线。
- 14B 学生: 15.11 FPS,首帧 0.54ms,Sync-C 7.59,Sync-D 7.23,FVD 107.88,FID 7.01。基本补上了同步差距(Sync-C 7.59 对真值 7.95),还比教师快约 40 倍。
- 对比 LatentSync: LatentSync 拿 Sync-C 8.10,但只有 3.23 FPS、FID 6.90。Lip Forcing 14B 在 FID 7.01 下快 4.7 倍,用约 0.5 的 Sync-C 换来一个数量级的延迟优势。
- 对比 MuseTalk: MuseTalk 跑 23.07 FPS、Sync-C 7.94,但 FID 9.68。Lip Forcing 的 1.3B 在 FID(6.76)和速度上胜过它,Sync-C 低于它。
- 对比 Wav2Lip: Wav2Lip 最快,479.60 FPS、Sync-C 最高 8.56,但 FID 24.15、FVD 384.82,画面很差。Lip Forcing 卖的是流式速度下的照片级真实,不是裸同步分。
- 加速比: 1.3B 比同规模双向模型快 17.6 倍;14B 比教师快 39.8 倍,比 LatentSync 快 4.7 倍。
局限与存疑
头条的 31 FPS 是 1.3B,而它的 Sync-C 最弱(6.88,低于所有双向基线也低于真值)。要最好的同步质量就得用 15.11 FPS 的 14B,所以”实时”和”最佳同步”不是同一个权重。评测只用 33 段 HDTF,是干净、正面、偏英语的数据;表里没有真实场景、多语种或侧脸的压力测试,尽管训练里掺了 VoxCeleb2。Wav2Lip 在裸同步分上还是赢它,说明基于 SyncNet 的 Sync-C 部分被那些画面差却得分高的老 GAN 方法钻了空子,使对比更复杂。摘录的表里没有对感知自然度的用户研究,具体局限放在附录而非正文结果里。复现两步调度和 Sync-Window 区间要依赖一堆细节(第 30 步落点、20-40 的 CFG 窗口、beta=2),它们绑在这个教师和数据集上,换一套未必照搬就成。
常见问题
Lip Forcing 是什么,和 LatentSync、MuseTalk 有何不同?
Lip Forcing 是首个用于视频转视频口型同步的自回归扩散方法,来自 KAIST AI 与 AIPARK。LatentSync 和 MuseTalk 双向处理整段视频,Lip Forcing 则把 14B 双向教师蒸馏成因果学生,每块两步去噪并流式输出。结果是 1.3B 跑 31.58 FPS,而 LatentSync 是 3.23 FPS,代价是同步分有所下降(Sync-C 6.88 对 8.10)。
Lip Forcing 怎么只用两步去噪就跑到 31 FPS?
它用分布匹配蒸馏把慢速多步双向教师蒸成因果学生,再只在两个 ODE 步 (0, 30) 上推理,运行时不开 CFG。1.3B 学生在 HDTF 上跑 31.58 FPS、首帧 0.32ms,比它出身的同规模双向模型快 17.6 倍。
Lip Forcing 里的 CFG 保真度与同步度权衡是什么?
CFG 调高(系数 4.5)能改善口型对音频的同步,却损害生成脸对参考的保真;调低(系数 1.0)保真但同步变松。没有一个固定系数两项都赢。Lip Forcing 的 Sync-Window DMD 按去噪步开关引导,只在敏感的 20-40 区间开,于是蒸馏后的学生推理期完全不用 CFG。
Lip Forcing 能追上教师的同步质量吗?
14B 接近,1.3B 不行。14B 学生 Sync-C 7.59(真值 7.95),还比教师快 39.8 倍。1.3B 学生用更多同步(Sync-C 6.88)换满血的 31.58 FPS 流式速度,所以最快的配置不是保真度最高的那个。
一句话:Lip Forcing 表明音频条件口型同步能靠把双向教师蒸成 2 步因果学生而做到 31 FPS 流式,但最快的 1.3B 模型为此牺牲了真实同步质量(6.88 Sync-C,LatentSync 是 8.10)。阅读 arXiv 原文。