SCAIL-2:端到端上下文条件的角色动画详解
SCAIL-2 把原始驱动视频直接拼进生成序列,不再走骨架中间表示,Studio-Bench 上 FVD 287 优于 Wan-Animate 的 305,且一个模型同时做动画和角色替换。
快速答案
SCAIL-2 把原始驱动视频拼接进生成序列来迁移动作,模型读到完整驱动帧,而不是一根姿态骨架或抠掉的背景。在 Studio-Bench 姿态驱动评测里,配上 SAM3D-Body 网格时它达到 FVD 287.11、SSIM 0.6453,对比 Wan-Animate 的 305.31 / 0.6340、VACE 的 387.52 / 0.5942。提升来自端到端驱动设计和合成数据管线,不是换了底座:模型是对 Wan2.1-14B-I2V 的全量微调。一个模型覆盖单角色动画、零样本多角色,以及角色替换。
中间表示的问题
姿态驱动方法先把驱动视频转成骨架或抠背景,再从中生成。骨架编码不了的信息在生成前就丢了:手与物体的接触、精细服饰、两个角色怎么互动。论文认为正是这个有损瓶颈,把已有方法在复杂动作上的上限压住了。
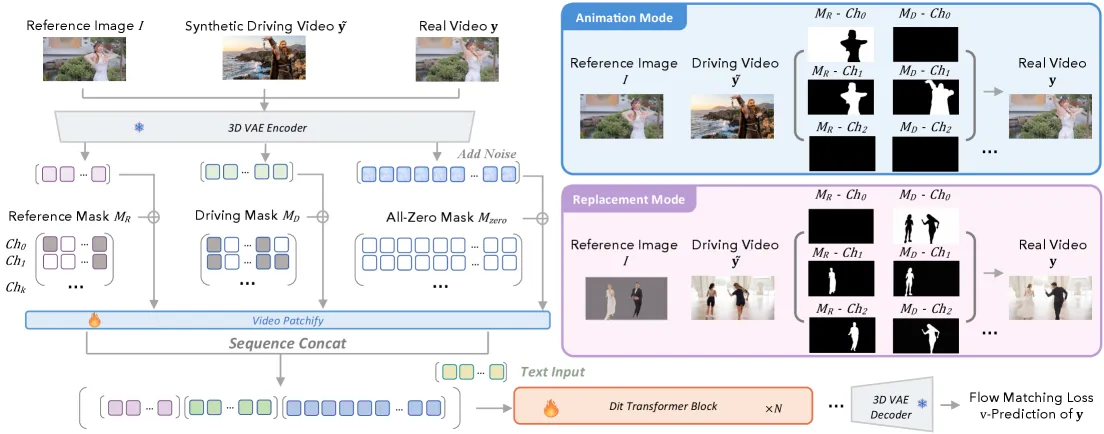
SCAIL-2 去掉了中间表示。I2V 底座输入 [z_ref; z_t; z_driv],即参考 token、含噪视频 token、驱动 token 的拼接,驱动 token 沿宽度轴加一个固定偏移,跟输出帧在空间上分开。驱动视频以原始像素作条件,模型能直接从中取动作、互动和场景细节。
一个模型怎么覆盖多任务
光靠端到端拼接,模型还分不清该保留参考背景(动画)还是驱动背景(替换),也分不清某段动作属于哪个角色。SCAIL-2 在输入上叠了一组上下文掩码通道。一个环境开关通道,标记背景取自参考图还是驱动视频。六个绑定槽通道(K=6,共叠 28 个通道),规定动作只在同一槽的角色内流动,这样在多角色场景里隔离身份,让远处的角色共用一个槽还能支持超过六个角色。Mode-Specific RoPE 负责区分动画与替换的布局。
训练时的掩码只来自参考图和驱动序列,从不来自真值,去噪 latent 的掩码全为零。论文把这条当作与既有条件方案的根本区别。
重活在数据管线
端到端监督需要的成对数据基本不存在,SCAIL-2 自己合成。一个智能体循环(候选选择器、提示编排器、质量检查器,加一个强多参考图生成模型)从人物数据集里造出合理的参考图,再用姿态驱动生成器把它们动画成对。产出就是 MotionPair-60K:约 31,895 对 SCAIL 单角色动画、13,847 对来自 Wan-Animate、MoCha 的 9,249 单角色和 4,385 多角色替换对,以及约 100,000 对姿态提取数据,按 60/20/20 采样。
因为真实视频充当监督,模型被引导去组合各项能力,最终能超过造出它训练数据的那些生成器。这是承重的论点:收益来自端到端范式加反向驱动数据,而非底层生成器本身。
Bias-Aware DPO
合成数据在细节区域带瑕疵。SCAIL-2 跑了 400 步 DPO 后训练,用一个按掩码加权的偏好损失(Bias-Aware DPO)把偏好信号聚焦到有偏差的区域,再配一个对正样本的 SFT 项。目标是补合成数据做错的精细区域的保真度。
关键结果
- Studio-Bench 姿态驱动(表 2): SCAIL-2 + SAM3D-Body 网格 SSIM 0.6453 / PSNR 19.09 / LPIPS 0.2231 / FVD 287.11,优于 Wan-Animate(0.6340 / 305.31),明显优于 VACE(0.5942 / 387.52)和 UniAnimate-DiT(0.6367 / FVD 480.15)。
- 网格胜过骨架,且零样本: 把 NLF-Pose 骨架换成 SAM3D-Body 网格,SSIM 从 0.6370 升到 0.6453,而模型训练时从没见过网格输入,说明更丰富的条件喂进了更多可用信息。
- Video-Bench(表 3): 成像质量 4.43(最高,SteadyDancer 4.41),外观一致性 4.38(最高),时序一致性 4.18。
- 人工评测(GSB): 单角色动画上全指标胜过开源基线,接近闭源 Kling 3.0;多角色是零样本,身份隔离上领先。
- 消融(Video-Bench): 完整模型成像质量 4.63,去掉绑定槽降到 4.47,去掉替换任务降到 3.90,绑定掩码和任务统一都有贡献。
这些应读作:相对 Wan-Animate、SteadyDancer、VACE 等开源基线的跨身份动画收益,闭源 Kling 3.0 是更难的参照,模型只是接近。
这些数字没有证明什么
最亮眼的 FVD 收益依赖配上 SAM3D-Body 网格;作纯骨架驱动生成器时,论文形容它的 SSIM/PSNR 一般,所以一部分胜势骑在更强的驱动表示上,而非模型本身。多角色领先是零样本,亮眼,但意味着它押在数据构造能否在没训过的输入上撑住。论文也承认 Bias-Aware DPO 难为精细区域找到可靠正样本,所以人脸和小细节的保真度仍是开放问题。整套方法依赖合成数据,其上限由造数据的生成器定。
对开发者的判断
如果你跑姿态驱动动画管线,信息在骨架那步丢了,这里能复现的点是拼接原始驱动视频加上下文掩码,不是新架构,它能套在现成 I2V 底座上。代价不小:在 64 张 H100 上对 14B 模型全量微调约一周,训练前还得先搭一条合成成对数据的管线。没有这套数据引擎的团队拿到的最少,因为绑定槽和替换模式只有在精选成对数据就位后才生效。需要盯的是精细区域保真,论文把它留给了未来工作。
局限与存疑
SCAIL-2 除了自己 64-H100-周这个数字,没给和基线的训练成本对比,所以相对姿态驱动方法的效率权衡没交代。外部有效性靠 Studio-Bench、X-Dance,以及作者自建的替换基准,而最强的姿态驱动数字要在回路里接一个外部网格提取器。合成数据依赖是结构性局限:保真度被生成器封顶,精细区域可靠正样本难拿,口型同步和面部表情被点名为尚未处理。数据子集和权重承诺在项目页发布,复现就看这次发布。
常见问题
SCAIL-2 是什么?
SCAIL-2 是智谱 AI 与清华的端到端可控角色动画框架,把原始驱动视频拼进生成序列,而不是转成姿态骨架或抠背景。它在 Studio-Bench 上 FVD 287.11,Wan-Animate 是 305.31,跑在微调过的 Wan2.1-14B-I2V 底座上。
SCAIL-2 和 Wan-Animate 这类骨架方法有什么区别?
姿态驱动方法把驱动视频转成骨架,在生成前就丢掉手物接触和互动细节。SCAIL-2 把原始驱动帧以上下文方式喂入,模型直接读到这些信息,这也是网格驱动信号能把它的 SSIM 零样本提到 0.6453 的原因。
MotionPair-60K 是什么,SCAIL-2 为什么需要它?
MotionPair-60K 是 SCAIL-2 用智能体编辑循环造的合成成对数据集:约 31,895 对 SCAIL 动画、13,847 对来自 Wan-Animate、13,634 对来自 MoCha 的替换数据,以及约 100,000 对姿态数据。端到端监督需要自然界不存在的成对动作数据,所以管线把它合成出来。
SCAIL-2 能做多角色动画和替换吗?
能。绑定槽掩码通道(K=6)把动作绑到特定角色,实现零样本多角色动画且身份隔离强;一个环境开关通道让同一模型做角色替换,胜过 Wan-Animate 和造它替换训练对的 MoCha 生成器。
一句话:SCAIL-2 用原始视频加上下文掩码驱动生成,绕开姿态骨架瓶颈,以一条沉重的合成数据管线换来更低的 FVD 和一个统一模型。阅读 arXiv 原文。