OmniDirector:无需配对数据的多镜头运镜克隆
OmniDirector 把参考视频的运镜复制到新生成的视频里,旋转误差降到 2.64 度,优于 CamCloneMaster 的 4.11,且不需要跨配对训练数据。
快速答案
OmniDirector 能把任意参考视频的运镜复制到新生成的视频里,而且不需要以往方法必备的跨配对数据集。在作者的 1094 条评测集上,它把旋转误差(RRE)降到 2.64 度,CamCloneMaster 是 4.11;旋转精度从 74.14% 提到 83.18%。差距最大的是多镜头转场:它的时序精度达到 96.52%,而 CamCloneMaster 只有 2.20%。关键做法是把相机轨迹画成一段网格视频,而不是用位姿矩阵或文字描述,这样模型就能从 180 万条普通互联网视频里自己造出训练对。
它绕开的跨配对数据难题
运镜克隆,就是把一段视频的相机运动(慢推、甩镜、环绕)套到新内容上。以往的标准做法需要跨配对数据:两段相机运动完全相同、画面内容不同的视频,让模型学会把运动和内容拆开。这种数据几乎不存在。对着不同主体把同一条轨迹拍两遍根本没法规模化,合成替代品又有域差。规模上不去,模型也就跟着卡住。
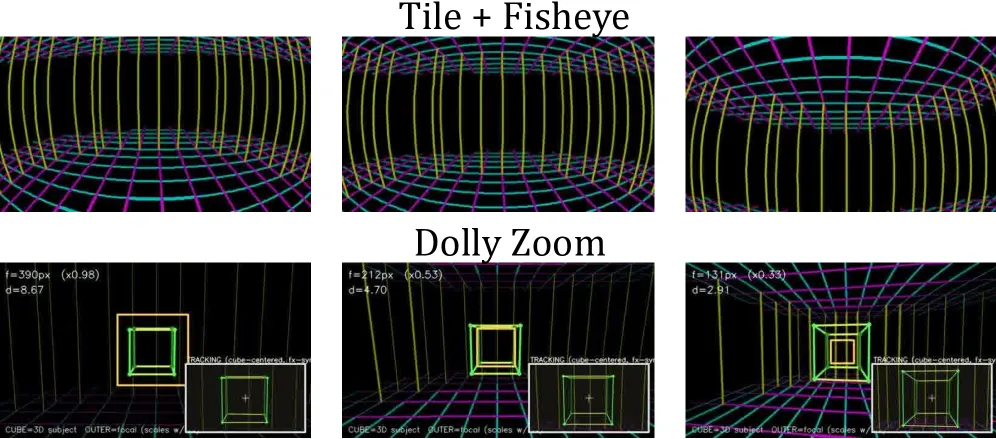
OmniDirector 换了相机的表示方式来跳过这个要求。它把相机轨迹渲染成一段相机网格:一间空房间里,红蓝正交线标出天花板和地板,黄色竖线标出墙面,一根管状结构勾出运动路径。这个网格直接由任意视频估计出的相机参数算出,于是每一段视频都成了自己的训练对。模型看到网格加一帧参考图,就要生成一段相机沿网格运动的视频,不再需要配对的第二段视频。
网格怎样驱动生成
主干是多模态扩散 Transformer。它把参考图、相机网格和带噪视频隐变量沿帧维度拼接,再让视觉 token 和文本 token 走各自的注意力通路。有个细节值得点出:30% 的训练样本是自重建,模型要从网格条件里重建网格本身,这逼它真去读懂几何,而不是凭感觉编一段看似合理的运动。
还有两点。网格能直接编码那些很难用语言描述的效果:用 Kannala-Brandt 模型表达鱼眼畸变,用焦距比例关系表达滑动变焦。另外有一套自适应无分类器引导调度,高噪声步注入网格(此时定整体运动),低噪声步注入其它信号(此时出细节)。去掉这套调度,旋转精度会从 83.18% 掉到 74.55%。
关键结果
- 旋转误差(RRE): 2.64 度,对比 CamCloneMaster 的 4.11、LTX-LoRA 的 5.67、Seedance 2.0 的 8.33,越低越好。
- 平移精度(T-Pre): 72.74%,CamCloneMaster 是 52.21%,在相机位置准确度上拉开 20 个百分点。
- 多镜头时序精度(Tem-Pre): 96.52%(转场落点误差在 3 帧内),CamCloneMaster 仅 2.20%,LTX-LoRA 为 38.94%。这一项才是真正拉开差距的地方,而不是单镜头精度。
- 内容泄漏: 帧泄漏 0.51%、镜头泄漏 3.38%,CamCloneMaster 是 1.60% 和 11.59%,说明参考视频的内容更少地渗进输出。
- 人工偏好(对比 CamCloneMaster 的 GSB): 相机 88.52% 不输,质量 95.69%,叙事 94.26%。
单镜头的旋转和平移提升是实打实的,但属于渐进改进。真正的看点是多镜头。以往的克隆方法基本没法重现一次剪辑加上随之而来的新机位;OmniDirector 把转场帧渲染成纯白,并分别生成镜头间和镜头内的相机提示,时序精度才从个位数跳到 90 多。
这些数字没有证明什么
96.52% 的时序精度用的是 3 帧以内的误差阈值,衡量的是转场是否落在大致正确的时刻,而不是转场后两个镜头在长时段里是否拍得连贯。作者把上限说得很直白:token 拼接的设计在视频明显变长时,难以维持长时记忆和时序一致。所以它在短的多镜头片段上很强,分钟级序列上还没验证。
读相机精度时要把估计器一起考虑。训练标签和评测都用 DPA-V3 估相机外参,焦距按长边的 0.8 倍近似。一个用同一套估计管线训练又用它打分的模型,会继承这套管线的系统偏差,而指标本身看不出来。
局限与存疑
长视频这个局限最该盯。运镜克隆最有用的场景恰恰是完整场景和长序列,而那正是 token 拼接退化的地方。论文结果都在 480p 上。分辨率和时长的空间都还没打开。
数据集是 180 万条互联网视频(电影、广告),用 TransNet-V2 做镜头检测筛过。这个分布偏专业拍摄,有利于画质,但也意味着运镜词汇贴近影视和广告的拍法,未必覆盖用户的任意意图。论文没有确认开放数据集或模型权重,所以外部还无法独立复现泄漏和多镜头那几个数字。
那些涌现能力(不重训就能用原始 RGB 或 Canny 边缘序列来驱动运动)只给了定性的泛化展示,没有量化,先当有潜力的 demo,别当已测能力。
常见问题
OmniDirector 怎么做到不用跨配对数据就能克隆运镜?
它把每段视频的相机轨迹渲染成 3D 网格(一间空房,用彩色线标出地板、天花板、墙面,再用管状结构画路径),网格由估计出的相机参数算出。因为网格来自同一段视频,每段片段都成了自己的训练对,不再需要两段运镜匹配的视频。
OmniDirector 在精度上和 CamCloneMaster 比怎么样?
它的旋转误差是 2.64 度,CamCloneMaster 为 4.11;平移精度 72.74% 对 52.21%。决定性差距在多镜头时序精度:96.52% 对 2.20%,因为 CamCloneMaster 本来就不是为重现转场设计的。
为什么 OmniDirector 的 96.52% 时序精度不代表全部?
这个分数用的是放置转场的 3 帧内阈值,衡量的是转场时机,不是跨镜头的长时连贯。作者指出 token 拼接的设计在长得多的序列上会丢失时序一致,而且所有结果都在 480p,长时长高分辨率的多镜头生成还没测过。
谁该用 OmniDirector,谁该再等等?
做短视频工具、用户想复制某个具体运镜(尤其是多镜头剪辑)的团队,现在就可以看看这套网格表示。需要分钟级、高分辨率、连贯序列的人应该再等,论文已经把长时记忆点名为待解瓶颈。
一句话:OmniDirector 把相机路径变成一段可自监督的网格,让运镜克隆变得可用,在多镜头转场上明显领先,但目前限于短的 480p 片段。阅读 arXiv 原文。