MulTaBench:40 个数据集的多模态表格学习基准
MulTaBench 是含 40 个数据集的多模态表格基准,每个任务都须同时用上表格与图像/文本。核心结论:针对目标微调的嵌入,在所有学习器上都胜过冻结嵌入。
快速答案
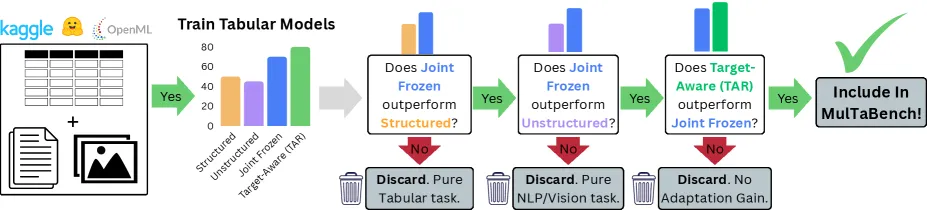
MulTaBench 是一个含 40 个数据集的基准,均分为 20 个图像-表格任务和 20 个文本-表格任务,其设计前提是:每个任务都必须同时依赖结构化表格与非结构化的图像或文本,缺一不可。它的核心结论是,针对预测目标微调过的”目标感知嵌入”,在所有被测表格学习器上都稳定胜过冻结的预训练嵌入——胜到小尺寸的微调嵌入能压过大尺寸的冻结嵌入。以 PetFinder 数据集为例,LightGBM 从仅用图像的 77.2% 升到双模态加目标感知表征的 85.7%,TabPFN-2.5 则从 81.1% 升到 88.0%。
为什么大多数”多模态表格”基准并不多模态
这篇论文真正扎实的贡献是筛选,而不是那个亮眼指标。很多数据集都把表格和图像或文本字段配在一起,但其中不少,光看表格就已包含全部信号,文本只是装饰。MulTaBench 设了两道关。联合信号标准要求同时用两种模态确实优于只用其一;约 23% 的候选文本-表格数据集没过这一关。任务感知标准会剔除那些”通用冻结嵌入已经把有用信息全捕捉到”的数据集;剩下数据集里又有 36% 没过。从已有基准里抽出的 56 个文本-表格候选,只有 41% 同时过了两关。图像-表格更难,文献来源的接受率约 31%,之后还靠人工策划补齐最终的 20 个。
这套筛选本身就是重点。一个”多出来的模态根本不起作用”的基准,教不了任何关于多模态融合的东西,而这类基准在学界比比皆是。
目标感知嵌入 vs 冻结嵌入
核心实验对比了两种把文本和图像变成表格模型可用特征的方式。冻结路线跑一个预训练编码器——文本用 e5,图像用 DINO-v3——把它固定的输出(经 PCA 降到约 30 维)喂给表格学习器。**目标感知表征(TAR)**路线则在抽特征之前,先在预测目标上微调编码器。
TAR 一致胜出。这个增益在全部五个主要学习器(LightGBM、CatBoost、TabM、TabPFNv2、TabPFN-2.5)和两种模态上都成立,并能推广到策划阶段没用过的学习器。最锋利的版本是:基于小嵌入模型的 TAR,反而压过了大冻结嵌入。把编码器做大确实有帮助,但补不上这道差距——让表征贴合任务,比堆编码器尺寸更要紧。
这些数据集长什么样
这 40 个数据集横跨医疗、电商等领域,样本量从约 400 到 114000 行,结构化特征列数从 1 到 245 列,分类与回归各占一半。编码器是标准化的:文本用 e5-v2-small(384 维)和 e5-large(1024 维),图像用 DINO-v3-small(384 维)和 DINO-v3-large(1024 维),默认 PCA 降到 30 维。除了五个策划学习器,作者还用 XGBoost、RandomForest、RealMLP、TabDPT、TabICLv2、TabSTAR、ConTextTab 和 AutoGluon-Multimodal 做压力测试,正是这一步让”TAR 优势并非某一模型家族的偶然”这个论断站得住脚。
关键结果
- 共 40 个数据集,精确均分为 20 个图像-表格和 20 个文本-表格,分类与回归各半。
- 目标感知胜过冻结:在全部五个主要学习器和两种模态上都成立,并能迁移到未见过的学习器。
- 小微调胜过大冻结:小编码器上的 TAR 压过大编码器的冻结嵌入,说明调表征比堆尺寸更重要。
- PetFinder,LightGBM:仅图像 77.2% → 双模态加 TAR 85.7%。
- PetFinder,TabPFN-2.5:仅图像 81.1% → 双模态加 TAR 88.0%。
- 策划很严:56 个文本-表格候选只有 41% 通过;约 23% 没过联合信号关,剩下的里 36% 没过任务感知关。
局限与存疑
作者对核心缺陷异常坦诚:策划流程用表格模型来判定哪些数据集合格,于是筛选标准与被评估的解法纠缠在一起。这带来偏置——策划用的那些模型本身无法在这个基准上被公平评分,而且很难事先预测哪些数据集会合格。为 TAR 微调编码器,还比冻结路线多出可观算力,论文把这部分放进了附录;对实践者来说,这个成本才是真问题,亮眼的准确率增益必须和它对冲着看。还有一个更细的隐忧:当单个 e5 模型在多个文本列上联合微调时,共享表征可能反而退化而非帮忙。此外策划模型没做超参优化,所以筛选阈值并未调优。这些都不至于推翻这个基准,但意味着”去微调你的嵌入”这条建议,带着一个算力星号和一个策划注脚。
常见问题
MulTaBench 是什么?
MulTaBench 是一个面向多模态表格学习的 40 数据集基准,均分为 20 个图像-表格和 20 个文本-表格任务。每个数据集都经过筛选,确保表格与图像或文本都真正被需要,因此它测的是融合能力,而不是”碰巧附带一张图的表格”。
MulTaBench 的主要发现是什么?
针对预测目标微调过的目标感知嵌入,在所有被测表格学习器上都稳定胜过冻结的预训练嵌入,而且小的微调编码器能压过大的冻结编码器。让表征贴合任务,比把编码器做大更重要。
MulTaBench 如何判定一个数据集是否真正多模态?
它用联合信号关(两种模态合用必须优于只用其一)和任务感知关(冻结嵌入不能已经把有用信号全捕捉)来筛。56 个文本-表格候选里只有 41% 同时过关;约 23% 没过联合信号,剩下的里 36% 没过任务感知。
MulTaBench 评估了哪些模型?
五个主要学习器驱动策划——LightGBM、CatBoost、TabM、TabPFNv2 和 TabPFN-2.5——稳健性检查再加上 XGBoost、RandomForest、RealMLP、TabDPT、TabICLv2、TabSTAR、ConTextTab 和 AutoGluon-Multimodal。文本用 e5 编码器,图像用 DINO-v3。
MulTaBench 最大的弱点是什么?
它的策划流程用表格模型来选数据集,于是合格标准与被测方法纠缠在一起,这些策划模型也无法在基准上被公平评分。目标感知方案还比冻结嵌入多出实打实的微调算力。
一句话:多模态表格基准只有在”多出来的模态真正起作用”时才有用——MulTaBench 先筛出这一点,再证明调表征胜过堆尺寸。阅读 arXiv 原文。