Role-Agent:一个 LLM 同时当智能体和环境
Role-Agent 让单个 LLM 既当智能体又当环境,自产过程奖励和课程。Qwen2.5-1.5B 上 ALFWorld 比 GiGPO 高 4.2%,WebShop 高 6.9%。
快速答案
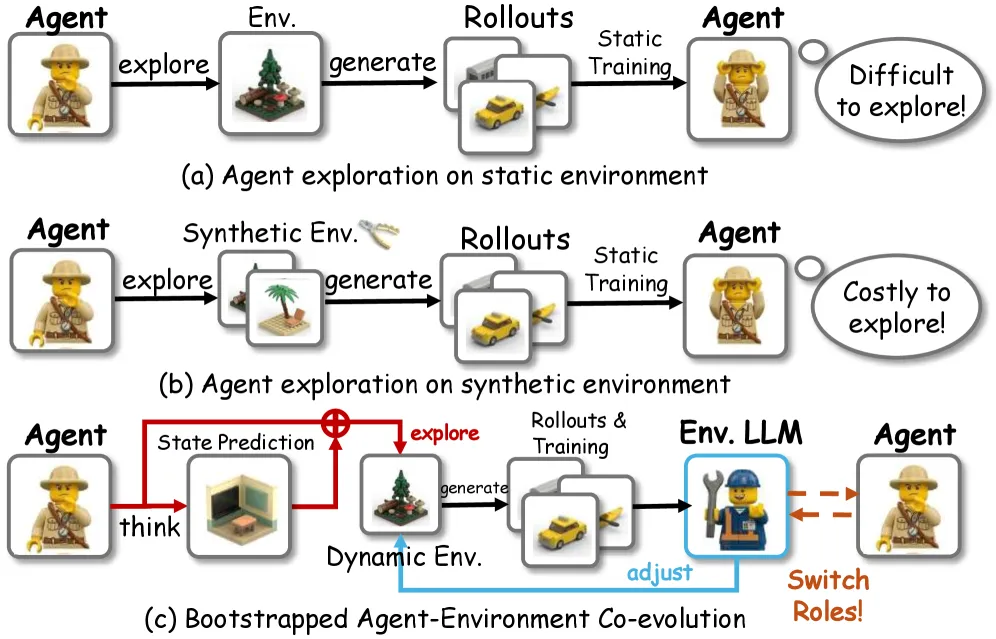
Role-Agent 让一个 LLM 在训练里同时扮演智能体和环境,自己生成奖励信号和任务课程,不需要外部奖励模型或手搭模拟器。Qwen2.5-1.5B-Instruct 上,ALFWorld 平均成功率 90.9%,GiGPO 基线是 86.7%;WebShop 是 71.9% 对 65.0%。提升真实但不大,几个基准平均约 4%。它来自挂在强 RL 基线上的两个低成本模块,不是新优化器。
两个角色,信号从哪来
方法分成 World-In-Agent(WIA)和 Agent-In-World(AIW),同一个模型在两者间切换。
WIA 里模型当智能体。每走一步,它还要预测接下来 H 步的环境状态。训练时用最长匹配子序列给预测和真实状态打分,折算成预测奖励。每步奖励变成:任务奖励乘以(1 加预测奖励)。逻辑是:能预测自己动作后果的智能体更懂动力学,这步动作更可信,该多给信用。
AIW 里同一个模型当环境。它读失败轨迹,用文字写出失败模式,再检索同类失败的任务,把采样向智能体当前的弱点倾斜。这是课程那一半:不再均匀采样,而是不断喂自己刚输掉的那类任务。
H 很关键。论文发现预测步长取最大步数的约 5% 最好,提到 10% 性能大跌,因为长程预测太噪,打分不可靠。
关键结果
- ALFWorld(Qwen2.5-1.5B): 平均成功率 90.9%,GiGPO 86.7%(+4.2%)。难子任务涨得多:Pick2 +13.6%,Look +11.0%。
- WebShop(Qwen2.5-1.5B): 71.9% 对 65.0%(+6.9%)。
- Qwen2.5-7B: ALFWorld 93.8%、WebShop 77.1%,GiGPO 是 90.8% 和 72.8%,平均约 +3.8%。基座越强,增益越小。
- 检索增强 QA(Qwen2.5-3B): 平均 45.8%,GiGPO 42.1%。多跳涨最多:2Wiki +8.2%,MuSiQue +5.2%。在 NQ 和 HotpotQA 上训,也测了域外集。
- 消融: 去掉 AIW,WebShop 掉 5.0%、ALFWorld 掉 3.4%;去掉预测奖励掉 3.6% 和 2.9%。两个削减版都还赢 GiGPO,说明各自独立有用。
预测奖励为什么有用
这是略读摘要会漏掉的细节。预测奖励和真实结果奖励的相关只有 0.41(点二列相关,p < 0.01),是个弱信号。它仍然有用,因为它不替代任务奖励,只是给任务奖励做乘法。0.41 已经够把模型能预见到的动作加权、把走运的动作降权,让优势估计更准,而不覆盖真实目标。预测质量本身在训练中上升,从初始约 0.60 升到收敛附近的 0.70 多,信号越练越干净。
这 4% 不能说明什么
别当它是新的 SOTA RL 算法。Role-Agent 是挂在 GiGPO 上的一个奖励调制层加一个课程启发式,平均增益约 4%。那些大幅单任务跳升(Pick2 +13.6%)都在最难、奖励最稀疏的子任务上,正是稠密内部信号最该起作用的地方,不代表平均水平。增益还从 1.5B 到 7B 收窄,暗示更强基座已经内化了部分 WIA 提供的东西。目前没有前沿规模上成立的证据。
局限与存疑
评测全是 Qwen2.5 的 1.5B 到 7B,没有大模型或非 Qwen 结果,跨模型族和前沿规模的迁移没验证。三类基准(ALFWorld、WebShop、搜索 QA)覆盖还行,但缺代码、工具调用和真实网页智能体,那里的动力学比模拟器乱得多。论文报了运行时开销,却没给干净的每涨一分要多少成本,和单纯加大 rollout 的取舍不清楚。AIW 抽失败模式依赖同一个 LLM 正确说出自己为什么失败,论文给了案例但没量化它说对的比例。arXiv 版本标注为在研工作。
常见问题
Role-Agent 是什么,双角色演化怎么跑?
Role-Agent 是一种 RL 训练方法,一个 LLM 在两个角色间切换。当智能体(World-In-Agent)时它预测未来状态,从预测和真实的吻合度拿过程奖励;当环境(Agent-In-World)时它分析自己的失败轨迹,检索同类任务再训。两个角色闭环共演化,模型自己提供奖励和课程。
Role-Agent 和 GiGPO 基线比怎么样?
Qwen2.5-1.5B 上 ALFWorld 90.9% 对 86.7%,WebShop 71.9% 对 65.0%;7B 上 93.8% 和 77.1% 对 90.8% 和 72.8%。平均增益约 4%,基座越强增益越小。
Role-Agent 的预测奖励只和结果相关 0.41,为什么还有用?
预测奖励是弱信号(和结果奖励点二列相关 0.41,p < 0.01),但它是给任务奖励做乘法,不是替代。这就够把模型能预见的动作加权、让优势估计更准。预测质量在训练中也上升,从初始约 0.60 升到收敛附近 0.70 多。
Role-Agent 去掉 Agent-In-World 会怎样?
去掉 AIW,WebShop 掉 5.0%、ALFWorld 掉 3.4%;去掉预测奖励掉 3.6% 和 2.9%。两个削减版都还赢 GiGPO,课程那半和奖励那半各自都有贡献。
一句话:Role-Agent 把单个 LLM 变成自己的奖励模型和课程,比 GiGPO 高约 4%,但它是只在小号 Qwen2.5 上验证过的调制层,不是前沿规模上已证明的方法。阅读 arXiv 原文。