AI Agents · Reinforcement Learning · LLM Reasoning
Role-Agent: One LLM Plays Both Agent and Its Own Environment
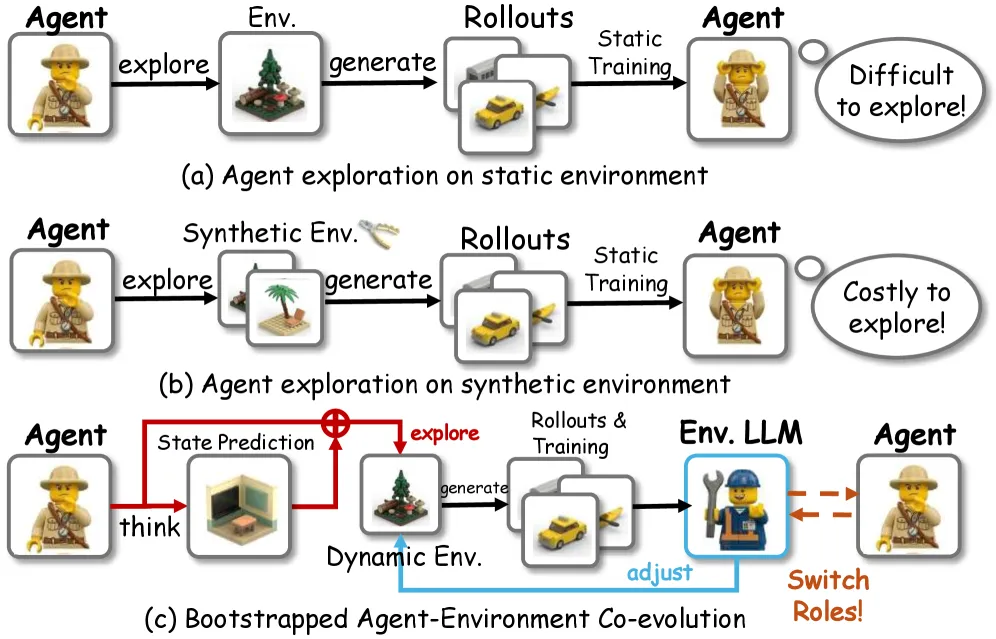
Role-Agent makes a single LLM act as agent and environment at once, generating its own process reward and curriculum. It beats GiGPO by 4.2% on ALFWorld and 6.9% on WebShop with Qwen2.5-1.5B.
Quick answer
Role-Agent lets one LLM play the agent and the environment in the same training loop, so it produces its own reward signal and its own task curriculum instead of needing an external reward model or a hand-built simulator. On ALFWorld with Qwen2.5-1.5B-Instruct it hits 90.9% average success versus 86.7% for the GiGPO baseline, and on WebShop 71.9% versus 65.0%. The gain is real but modest: about 4% averaged across benchmarks. It comes from two cheap additions stacked on a strong RL baseline, not a new optimizer.
The two roles, and where the signal comes from
The method names its two halves World-In-Agent (WIA) and Agent-In-World (AIW). The same model alternates between them.
In WIA the model wears the agent hat. After each action it also predicts the next H environment states. The training loop compares those predictions to the real states using a longest-matching-subsequence score, then folds that into a predictive reward. The task reward gets modulated by it: the per-step reward becomes the task reward times (1 + predictive reward). The idea is that an agent that can forecast what its action will do understands the dynamics better, so its action is more trustworthy and deserves more credit.
In AIW the same model wears the environment hat. It reads failed trajectories, writes down the failure mode in words, and retrieves training tasks that share that mode. Sampling then tilts toward the agent’s current weak spots. This is the curriculum half: instead of uniform task sampling, the model keeps feeding itself the kinds of tasks it just lost on.
H matters. The paper finds a prediction horizon of about 5% of the max step count works best; pushing it to 10% drops performance sharply, because long-horizon prediction is too noisy to score reliably.
Key results
- ALFWorld, Qwen2.5-1.5B-Instruct: 90.9% average success vs 86.7% for GiGPO (+4.2%). Hard subtasks gain most: Pick2 +13.6%, Look +11.0%.
- WebShop, Qwen2.5-1.5B-Instruct: 71.9% vs 65.0% (+6.9%).
- Qwen2.5-7B-Instruct: 93.8% on ALFWorld and 77.1% on WebShop vs 90.8% and 72.8% for GiGPO, roughly +3.8% average. The gain shrinks as the base model gets stronger.
- Search-augmented QA, Qwen2.5-3B-Instruct: 45.8% average vs 42.1% for GiGPO. Multi-hop sets move most: 2WikiMultiHopQA +8.2%, MuSiQue +5.2%. Trained on NQ and HotpotQA, evaluated on out-of-domain sets too.
- Ablation: removing AIW costs 5.0% on WebShop and 3.4% on ALFWorld; removing the predictive reward costs 3.6% and 2.9%. Both stripped versions still beat GiGPO, so each piece helps independently.
Why the predictive reward works at all
Here is the detail an abstract skim misses. The predictive reward correlates with the actual outcome reward at only 0.41 (point-biserial, p < 0.01). That is a weak signal. The method still helps because it does not replace the task reward; it scales it. A correlation of 0.41 is enough to up-weight credit on actions the model could foresee and down-weight credit on lucky ones, which sharpens advantage estimation without overriding the real objective. The prediction quality itself climbs during training, from about 0.60 alignment at init to the high 0.70s near convergence, so the signal gets cleaner as the agent improves.
What the 4% does not prove
Do not read this as a new state-of-the-art RL algorithm. Role-Agent is a modulation layer plus a curriculum heuristic bolted onto GiGPO, and the headline gain is roughly 4% averaged. The bigger per-task jumps (Pick2 +13.6%) are on the hardest, sparsest-reward subtasks, exactly where a denser internal signal should help most; they are not the average case. The gain also narrows from the 1.5B to the 7B model, which is a hint that a stronger base model already internalizes some of what WIA supplies. There is no evidence yet that the method holds at frontier scale.
Builder judgment
This is most useful if you are doing on-policy RL on small open agents (1.5B to 7B) for sparse-reward, long-horizon tasks where building a faithful simulator or training a reward model is expensive. The two additions are cheap to bolt onto an existing GiGPO or GRPO-style loop and need no extra labels. Watch the runtime: the paper’s per-step breakdown shows WIA and AIW add overhead on top of the baseline generation time, so the gain per wall-clock second is smaller than the gain per step. If you already have dense environment rewards or a clean simulator, the WIA half buys you less, and you may only want the failure-retrieval curriculum.
Limits and open questions
The evaluation is all Qwen2.5 at 1.5B to 7B. No large-model or non-Qwen results, so transfer to other model families and to frontier scale is untested. Three benchmark families (ALFWorld, WebShop, search QA) is a fair spread but still leaves out code, tool-calling, and real web agents where dynamics are far messier than a simulator. The paper reports runtime overhead but not a clean cost-per-point-of-gain, so the efficiency tradeoff against simply scaling rollouts is unclear. The AIW failure-mode extraction depends on the same LLM correctly naming why it failed; the paper shows case studies but no quantitative check on how often the extracted mode is right. The arXiv version is marked work in progress.
FAQ
What is Role-Agent and how does dual-role evolution work?
Role-Agent is an RL training method where one LLM alternates between two roles. As the agent (World-In-Agent) it predicts future states and earns a process reward from how well those predictions match reality. As the environment (Agent-In-World) it analyzes its own failed trajectories and retrieves similar tasks to retrain on. The two roles co-evolve in a closed loop, so the model supplies its own reward and curriculum.
How does Role-Agent compare with the GiGPO baseline?
On Qwen2.5-1.5B-Instruct it reaches 90.9% on ALFWorld vs 86.7% and 71.9% on WebShop vs 65.0%. On the 7B model it gets 93.8% and 77.1% vs 90.8% and 72.8%. The average gain is about 4%, and it shrinks as the base model gets stronger.
Why does Role-Agent’s predictive reward only correlate 0.41 with outcomes yet still help?
The predictive reward is a weak signal (0.41 point-biserial correlation with outcome reward, p < 0.01), but it multiplies the task reward rather than replacing it. That is enough to up-weight credit on actions the model could foresee and sharpen advantage estimation. Prediction quality also rises during training, from ~0.60 alignment at init to the high 0.70s near convergence.
What happens in the Role-Agent ablation without Agent-In-World?
Removing AIW drops WebShop by 5.0% and ALFWorld by 3.4%; removing the predictive reward drops them by 3.6% and 2.9%. Both stripped versions still beat GiGPO, so the curriculum half and the reward half each contribute on their own.
One line: Role-Agent turns a single LLM into its own reward model and curriculum and beats GiGPO by about 4%, but it is a modulation layer tested only on small Qwen2.5 models, not a proven frontier-scale method. Read the original paper on arXiv.