SwanSphere:从视频和文本流式生成空间音频
SwanSphere 流式生成与视频/文本同步的一阶环绕声,首块仅 0.21 秒出声,Frechet 距离压到 120.28(OmniAudio 为 157.67),质量与实时兼得。
快速答案
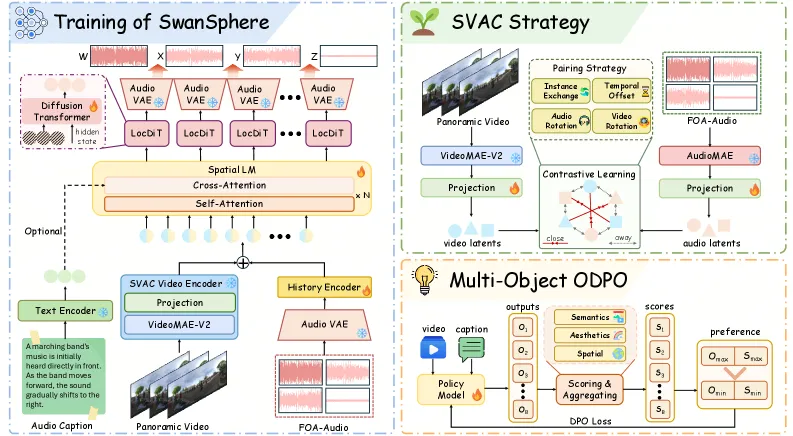
SwanSphere 生成的是空间音频,也就是四通道一阶环绕声(FOA),它编码了每个声音在三维空间中的方位。它以流式方式生成:第一块音频在 0.21 秒内就能输出,而不必等整段渲染完。它既能由视频驱动(让声音方向匹配画面中的运动),也能由文本驱动。结构上分两段:一个空间语言模型(Spatial LM)自回归地预测语义 token,再由局部扩散 Transformer(LocDiT)通过流匹配把这些 token 解码成连续的 FOA 波形。在视频到空间音频任务上,它的 Frechet 距离(FD)做到 120.28,而 OmniAudio 是 157.67,方向(角度)误差 1.03 度。模型规模 1.09B 参数,已被 ICML 2026 接收。
流式空间音频为什么难
为视频生成空间音频要同时做对两件事:声音听起来对(音色、保真度),以及声音来对方向(一辆车从左划到右,声像也要跟着平移)。多数早期系统把这当成离线批量生成:喂整段视频,等待,拿到整条声轨。这让实时和交互场景(数字人直播、AR、游戏音频)几乎没法用,因为延迟随片段长度线性增长。最朴素的补救是把音频切块,但独立切块会破坏空间连贯性:相邻块之间方向和音色会漂移。SwanSphere 的赌注是:用带显式因果条件的自回归骨干,既能边生成边出声,又能让方向在块与块之间保持一致。
SwanSphere 怎么工作
整条流水线分两段。空间语言模型吃进视频特征(来自 VideoMAE 编码器)或文本,自回归地预测一串语义嵌入。这是让流式成为可能的因果部分,因为每个新块都以前面的内容为条件。**局部扩散 Transformer(LocDiT)**再用流匹配把这些嵌入解码成高保真连续空间音频,运行在一个专为环绕声设计的 4 通道 FOA-VAE 的隐空间里。
真正出力的是两个训练设计。空间视频-音频对比学习(SVAC)把画面里的运动和音频的方向内容对齐,让模型学到”物体向右移动就该让声音从右边来”,而不只是生成听起来合理的噪声。在此之上,一个多目标在线 DPO阶段同时在多个维度(保真度、空间准确度、同步性)做偏好优化,而不是只盯单一奖励。考虑到”好的空间音频”本身就是多准则的,这个选择是合理的。
数据流水线内部
空间音频数据集几乎不存在,所以很大一部分贡献其实是一套自动标注流水线。主数据集 SwanSphere 约有 16.5 万对视频-音频(约 458 小时),来自 Sphere360、YT-Ambigen 以及新采集的 YouTube 片段,留 5% 作测试。为了打好音质底子,作者还在约 100 万条来自 AudioCaps、VGGSound、WavText5k、AudioSet 的样本上做课程学习,统一转成伪 FOA 格式。另有一个约 3,100 条的空间字幕集(留 300 条评测)支撑文本到空间音频任务。说句实在话:有监督的空间字幕集偏小,团队靠伪 FOA 转换来凑规模。务实,但很可能也是空间对齐能做到多细致的天花板。
关键结果
- 首块延迟 0.21 秒,整段生成 9.13 秒。流式是真正的卖点,0.21 秒已经够得上交互级。
- 视频到空间音频 FD 120.28,OmniAudio 为 157.67,KL 散度 1.36 对 1.93,角度误差 1.03 度对 1.27 度,质量和定位双双更好。
- 文本到空间音频 FD 142.80,OmniAudio 为 174.13,KL 1.43 对 1.83。换成文本驱动时同样的差距依然成立。
- 主观评分 MOS-SQ 4.32、MOS-AF 4.44(视频到空间音频),逼近真值的 4.60 和 4.58。在音质和视听贴合度上,人类听感已接近真实。
- SELD 加权余弦相似度 0.63,OmniAudio 为 0.41,在声音事件定位与检测探针上拉开明显差距,这是”声音方位对不对”最直接的检验。
- 1.09B 参数,中等体量,不是巨型模型。
局限与存疑
作者坦言空间字幕大多只描述单一主导声源,所以多声源场景(比如多个乐器从不同方向同时演奏的音乐会)没有被充分建模,细粒度的空间解耦受限。这正是真正的瓶颈:单声源上漂亮的定位,未必扛得住嘈杂的复音场景。大规模课程数据依赖伪 FOA 转换,也意味着很大一部分训练信号是合成的空间信息,而非实测。再者,在 5% 同分布测试集上的 FD/KL 几乎说明不了对域外视频的泛化。谁该跳过:当下需要密集多声源空间场景的人,以及没有 FOA 播放/渲染链路、根本用不上环绕声输出的人。
常见问题
SwanSphere 是什么,它生成什么?
SwanSphere 是浙江大学的一个 1.09B 参数模型,用于流式生成空间音频,具体是带方向信息的四通道一阶环绕声(FOA),可由输入视频或文本描述驱动。该工作已被 ICML 2026 接收。
SwanSphere 是怎么把空间音频生成的延迟做低的?
它用了因果自回归扩散 Transformer:空间语言模型逐块预测语义嵌入,因此不必等整段输入处理完就能开始生成,再由局部扩散 Transformer 用流匹配逐块解码。由此实现 0.21 秒的首块延迟,而不是等整段渲染完。
在视频到空间音频任务上,SwanSphere 比 OmniAudio 强吗?
按论文给出的基准,是的:SwanSphere 的 FD 为 120.28(OmniAudio 157.67),角度误差 1.03 对 1.27 度,SELD 加权余弦相似度 0.63 对 0.41。需要注意的是复杂多声源场景仍未建模,所以这一领先在单一主导声源的内容上最明显。