Retrieval-Augmented Generation · Language Models · Efficient AI
Active Learners as Efficient PRP Rerankers: Fewer LLM Calls
Treating pairwise LLM reranking as active learning, a tournament selector hits 68.00 NDCG@10 on TREC DL while cutting LLM calls 3-5x versus sorting-based PRP, plus a randomized-direction oracle that debiases in one call.
Quick answer
This paper reframes pairwise ranking prompting (PRP) — asking an LLM “is document A more relevant than B?” — as an active learning problem, and shows the reframing pays off. Their tournament-style selector (Mohajer) reaches 68.00 NDCG@10 on TREC DL with Flan-T5-XL, while using 3-5x fewer LLM calls than sorting-based PRP baselines. The key trick is a randomized-direction oracle that flips comparison order at random with a single LLM call per pair, converting the well-known position bias of LLM judges into unbiased noise that active rankers tolerate.
Why sorting-based PRP wastes calls
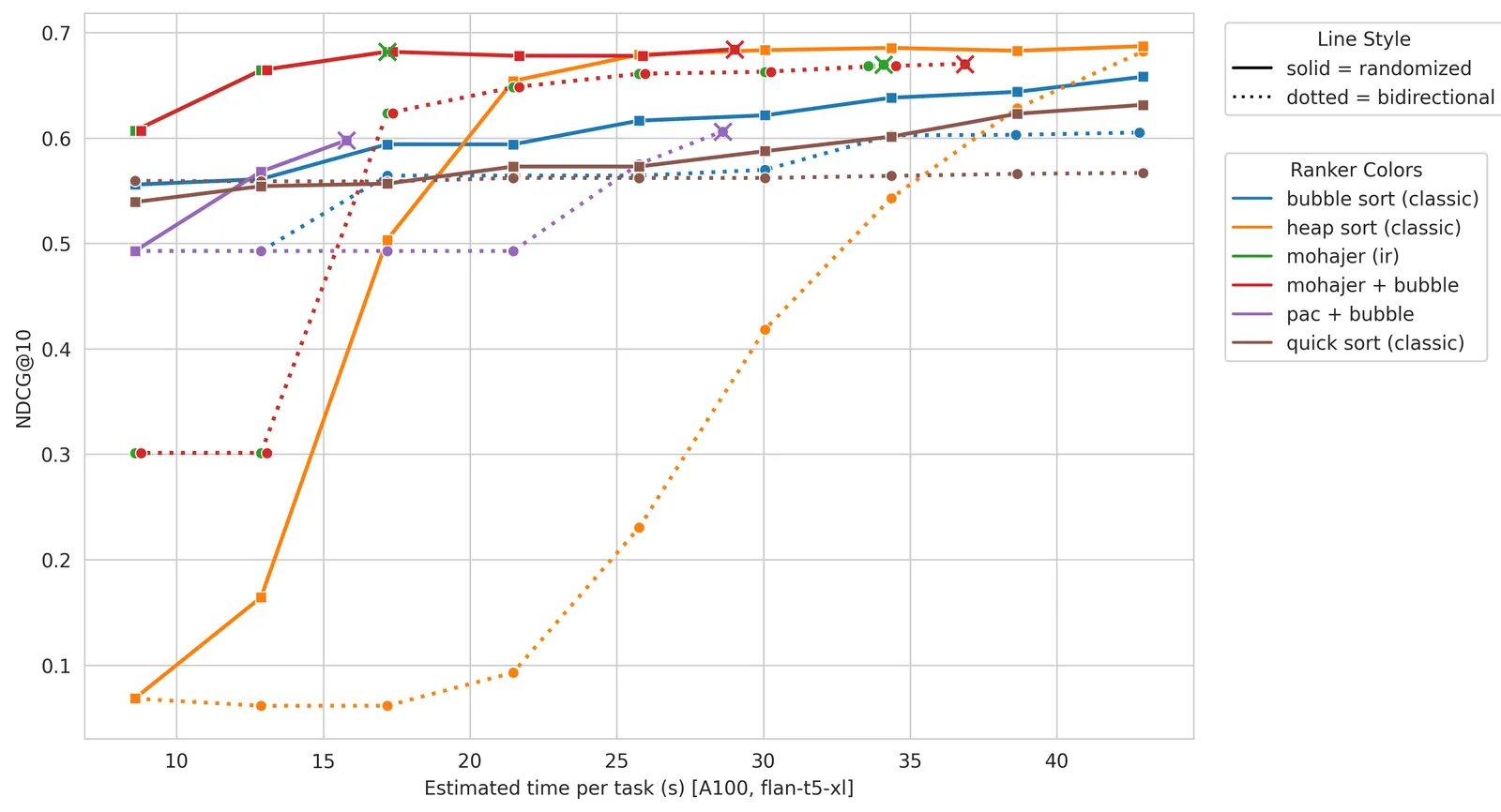
Pairwise ranking prompting is accurate but expensive: it compares documents two at a time, and the obvious way to turn comparisons into a ranking is a sort. The catch is that LLM pairwise judgments are, as the authors put it, “noisy, order-sensitive, and sometimes intransitive” — A beats B, B beats C, but C beats A. Classical comparison sorts assume a clean total order, so they either burn calls re-checking unstable pairs (BubbleSort sliding windows can run 941-1669 calls per task) or make confident decisions from a single shaky comparison. Neither is what you want when each comparison is a forward pass through a multi-billion-parameter model.
How active ranking changes the budget
The insight is that you rarely need the full ranking — top-k retrieval only needs the top documents ordered correctly. Active ranking algorithms spend their comparison budget where it matters: they model the ranking as something to be learned from informative queries, not sorted exhaustively. The paper benchmarks several such selectors against sort baselines (BubbleSort, HeapSort, QuickSort), with two standouts: Mohajer, a tournament-style top-k selector, and an optimized PAC (probably-approximately-correct) procedure. Both decide which pairs to compare adaptively, so they stop early once the top of the list is stable rather than completing a sort.
The randomized-direction oracle
Position bias — an LLM systematically favoring the first or second document regardless of content — is the quiet killer of PRP. The standard fix is a bidirectional oracle: ask A-vs-B and B-vs-A, then reconcile, which doubles the calls. This paper’s alternative is a randomized-direction oracle: for each pair, flip a coin on which document goes first, then issue a single call. Over many comparisons the bias averages out into zero-mean noise, and active rankers are built to tolerate noise. You get most of the debiasing for half the calls. This is the paper’s cleanest idea, and notably the authors admit they cannot yet explain why it works as well as it does theoretically.
Key results
- 68.00 NDCG@10 on TREC DL (DL2019/2020, Flan-T5-XL) with the Mohajer selector under the randomized-direction oracle, at a budget of B=250 and B=300 calls.
- +9.67 NDCG@10 over BubbleSort under the bidirectional oracle at B=300: Mohajer scores 66.09 vs BubbleSort’s 56.42 at the same call budget.
- 3-5x fewer LLM calls end-to-end on BEIR-style tasks (N=100, K=10): active selectors use 184-345 calls per task (55.0-57.3 NDCG@10) versus 941-1669 calls for BubbleSort PRP (56.8-60.4 NDCG@10).
- Evaluated across model scales — Flan-T5-L, Flan-T5-XL, Flan-T5-XXL, and Qwen3-4B-Instruct — and BEIR datasets including COVID, Robust04, Touché, SciFact, DBPedia, and FiQA.
Limits and open questions
The honest reading: this is an efficiency-quality trade, not a free win. On the end-to-end BEIR numbers the active selectors sit slightly below BubbleSort on raw NDCG@10 (55.0-57.3 vs 56.8-60.4) — the selling point is that they reach near-parity quality for a fraction of the calls, not that they rerank better. The authors are candid that the randomized-direction gains are “empirically consistent but not theoretically explained,” that they measured latency incompletely and did not implement parallelization (which would change the call-budget story for sorts that parallelize well), and that prompt design, model family, and decoding settings all move the numbers. There is also no ablation on the PAC hyperparameter m. So the case is strongest in genuinely call-constrained settings — small budgets, expensive judges — and weaker if you can batch or parallelize comparisons cheaply.
FAQ
What does “Active Learners as Efficient PRP Rerankers” actually propose?
It proposes treating LLM pairwise reranking as active learning: instead of sorting documents with exhaustive pairwise comparisons, use active-ranking selectors (notably Mohajer and an optimized PAC method) that adaptively pick which pairs to compare, plus a randomized-direction oracle that debiases comparisons with one call each.
How much does the active PRP approach reduce LLM calls?
On BEIR-style tasks it uses 3-5x fewer calls than sorting-based PRP — roughly 184-345 calls per task versus 941-1669 for BubbleSort — while landing within a couple of NDCG@10 points of the more expensive baseline.
What is the randomized-direction oracle in this paper?
For each document pair it randomly chooses which document is presented first, then makes a single LLM comparison call. This turns an LLM’s systematic position bias into zero-mean noise, giving most of the benefit of a two-call bidirectional oracle at half the cost.
Does the active PRP method beat standard PRP on ranking quality?
Not on raw quality in the end-to-end setting — BubbleSort PRP can score slightly higher NDCG@10. The contribution is efficiency: matching quality closely while spending far fewer LLM calls, which is what matters when each comparison is an expensive model call.
One line: reframe pairwise LLM reranking as active learning, randomize comparison direction, and you keep most of the ranking quality for a fraction of the calls. Read the original paper on arXiv.