Reinforcement Learning · AI Agents · LLM Reasoning
APPO: Agentic Procedural Policy Optimization for RL Agents
APPO branches RL rollouts at high-uncertainty, high-influence tokens instead of tool-call boundaries, lifting Qwen2.5-7B by 3.9 points over ARPO across 13 math, multi-hop, and deep-search benchmarks.
Quick answer
APPO is an agentic RL training method that places its credit-assignment effort at the tokens that actually decide an outcome, not at tool-call boundaries. On Qwen2.5-7B-Instruct it averages 62.2 across 13 benchmarks versus 58.3 for ARPO, a 3.9-point gain; on Llama3.1-8B it reaches 57.4 versus 55.3. The gain comes from the training recipe, not a stronger base model: the same checkpoints are fine-tuned, so any improvement is the RL procedure and the rollout tree, not new pretraining.
The credit-assignment problem APPO targets
Agentic RL usually rewards a whole trajectory with one outcome signal, then has no clean way to say which intermediate step earned the reward. Prior agentic methods such as ARPO patch this by branching rollouts at heuristic units like tool-call boundaries. The paper’s Figure 1 analysis argues that this is the wrong anchor: high-entropy tokens do not cluster at tool calls, and high entropy on its own is a poor signal of decision significance because some entropy peaks are just lexically rare words (“march”, “november”) rather than task-critical forks.
That observation drives the whole design. If you branch where the model is merely uncertain about wording, you spend rollout budget exploring noise. APPO tries to branch only where uncertainty coincides with downstream influence.
How the branching score works
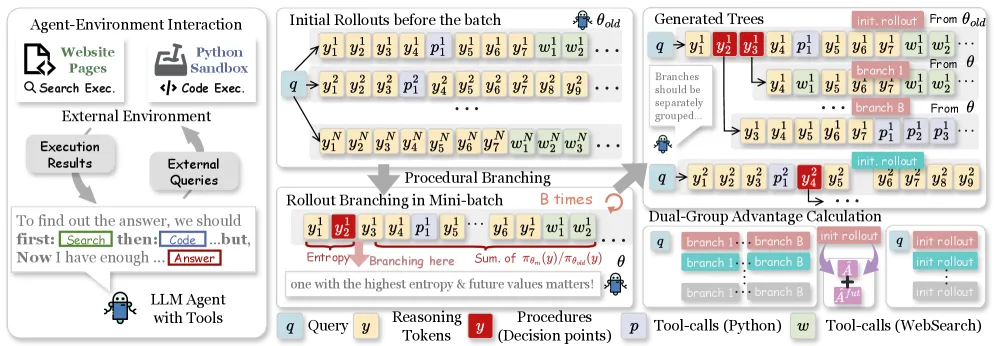
APPO scores every token with a product of two normalized signals (Eq. 5). One factor is token entropy, the model’s local uncertainty. The other is an accumulated, discounted importance-sampling ratio that estimates how much the continuation after that token shifts under the current policy, a proxy for “how much does this choice change the future.” Both are z-score normalized within a rollout, then multiplied, so a token scores high only when it is both uncertain and consequential.
The rollout loop then works like a tree. Generate N initial full rollouts, pick the top-B tokens by branching score in each, resample continuations from those points, and keep expanding until a fixed budget M is spent. The reported sweet spot is N=4, B=3 at M=16; balanced settings beat extreme ones, which is a sign the method depends on spreading budget rather than branching everywhere.
Procedure-level advantage scaling
The second half is how reward is turned into per-token credit. APPO groups the initial rollouts and the branched continuations into separate advantage groups (dual-group) to avoid mixing distributions that came from different sampling conditions. It then adds a future-aware advantage term, again built from the discounted likelihood ratio, and multiplies it into the base advantage so that tokens with stronger downstream influence receive larger credit. The intent is to push reward onto the sparse forks that mattered instead of smearing it evenly across the trajectory.
Key results
- Qwen2.5-7B-Instruct, 13-benchmark average: APPO 62.2 vs ARPO 58.3 (+3.9). AIME24 climbs to 36.7 from 30.0.
- Llama3.1-8B-Instruct, 13-benchmark average: APPO 57.4 vs ARPO 55.3 (+2.1). AIME24 reaches 30.0 vs 23.3.
- Deep search (GAIA): Qwen3-8B 42.7 vs 38.8 (+3.9); Qwen3-14B 46.6 vs 43.7 (+2.9).
- Benchmark spread: 5 math (AIME24, AIME25, MATH500, GSM8K, MATH), 5 knowledge-intensive multi-hop (WebWalker, HotpotQA, 2WikiMultihopQA, Musique, Bamboogle), 3 deep-search (GAIA, Humanity’s Last Exam, Xbench).
- Ablations (Qwen2.5-7B, 5 knowledge tasks): removing the future-aware advantage costs 3.4 points, dropping dual-group costs 2.1, and replacing the full branching score with entropy-only costs 1.8. The future term is the single biggest lever.
Read these as agentic-RL training gains over a matched RL baseline. The comparison set includes classic RL recipes (GRPO, Reinforce++, DAPO, GPPO, CISPO) and agentic ones (GIGPO, ARPO), so the headline is “better RL procedure,” with ARPO as the relevant comparator rather than an untrained base model.
What the numbers do not prove
A 3.9-point average is a recipe improvement of a few percent on top of an already RL-tuned agent, not a capability jump from the base model. The dual-group and future-aware terms are coupled to APPO’s own tree rollout, so the gains are not portable as a drop-in loss on an arbitrary trajectory dataset; you need the branching machinery too. The Pass@K curves widen as k grows, which suggests APPO mainly reshapes the distribution of candidate trajectories rather than producing one reliably better answer, so single-sample deployments may see less of the effect than the averages imply.
Builder judgment
If you already run agentic RL with tool calls and your branching is anchored at tool boundaries, APPO is worth reproducing, because the cheapest part to adopt is the branching-score criterion for choosing where to explore. Teams without an RL training stack get little here; this is a training-time method, not an inference trick. The honest watch item is cost: branching plus the accumulated importance-ratio computation add overhead the paper does not quantify in tool-call or token terms, and it claims only “comparable” tool-call counts without a hard number.
Limits and open questions
The paper reports no explicit compute, wall-clock, or token-cost accounting for the branching tree, so the efficiency claim rests on “comparable tool calls” rather than a measured budget. External validity is the usual caveat: results are on Llama3.1-8B, Qwen2.5-7B, and Qwen3-8B/14B with specific benchmark splits, and the deep-search numbers lean on GAIA, where small absolute gains can be noisy. Reproducibility depends on whether the branching budget, scoring hyperparameters, and reward setup are released in enough detail to rebuild the tree, since the advantage scaling is meaningless without it.
FAQ
What is APPO (Agentic Procedural Policy Optimization)?
APPO is an RL fine-tuning method for LLM agents that selects branching points by a score combining token entropy and a discounted importance-sampling ratio, then applies procedure-level advantage scaling so high-influence tokens get more credit. On Qwen2.5-7B it averages 62.2 across 13 benchmarks versus 58.3 for ARPO.
How is APPO different from ARPO and tool-call-boundary branching?
ARPO branches rollouts at heuristic units like tool-call boundaries. APPO argues high-entropy, decision-critical tokens do not cluster at tool calls, so it branches at the tokens that are both uncertain and have downstream influence, which is what drives the 3.9-point Qwen2.5-7B gain over ARPO.
Does APPO improve the base model or only the RL training?
Only the RL training. The same base checkpoints (Llama3.1-8B, Qwen2.5-7B, Qwen3-8B/14B) are fine-tuned, so the 2.1-to-3.9-point gains are attributable to the rollout-tree procedure and advantage scaling, not to better pretraining or a larger model.
Which APPO component matters most in the ablation?
The future-aware advantage term. Removing it costs 3.4 points on Qwen2.5-7B knowledge tasks, more than dropping dual-group grouping (2.1) or reducing the branching score to entropy-only (1.8).
One line: APPO is a credit-assignment recipe for agentic RL that branches where decisions matter rather than at tool calls, buying a few points over ARPO with added rollout cost the paper does not fully price. Read the original paper on arXiv.