AI Agents · AI for Science · Code Generation
EurekAgent: Environment Engineering for AI Science
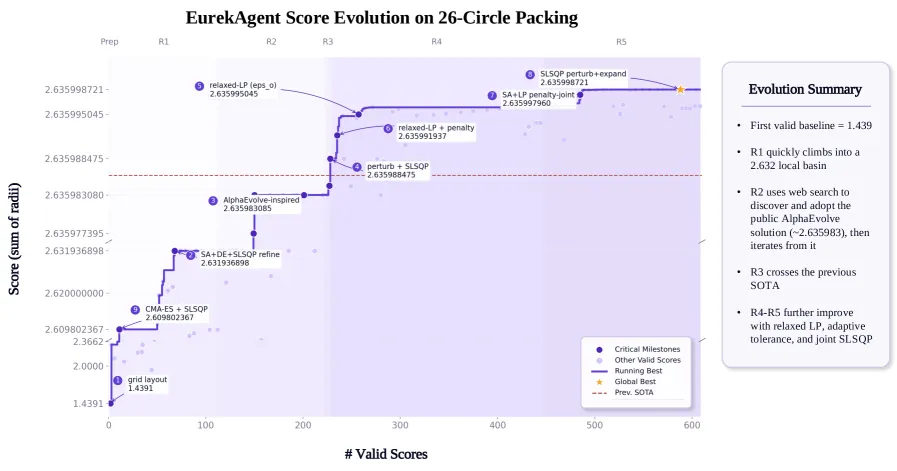
EurekAgent argues the bottleneck is agent environment design, reporting 2.635999 on 26-circle packing, 2005.03 us TriMul, and 85.71% any-medal on a seven-task MLE-Bench subset.
Quick answer
EurekAgent’s thesis is that autonomous scientific discovery is becoming less about hand-prescribing the agent workflow and more about engineering the environment around a strong CLI agent. The system uses permissions, artifacts, budgets, and human interfaces to make exploration productive and auditable. The reported results are eye-catching: 2.635999 on 26-circle packing, 0.380870 on Erdos minimum overlap, 1.502861 on first autocorrelation inequality, 2005.03 microseconds median on TriMul, and 85.71% any-medal on a seven-task MLE-Bench Lite subset.
The environment replaces the fixed workflow
EurekAgent does not define a rigid scientific method for every task. It runs a prepare-propose-implement loop around off-the-shelf CLI agents. The environment decides what the agent can see, where it can write, how official scores are recorded, how previous attempts are preserved, and when budget warnings appear.
Permissions engineering is the safety layer. Agents can use tools and internet resources, but hidden evaluators and authoritative result files stay outside the editable workspace. Same-round implementation sessions are isolated, which reduces accidental leakage between candidate solutions.
Artifact engineering is the memory layer. The filesystem and Git history store preparation summaries, proposal manifests, hypotheses, code, scores, and transcripts. Budget engineering makes time and API cost explicit. Human-in-the-loop engineering provides terminal and web monitors so a person can inspect or redirect runs without turning the system into manual execution.
Key results
- On 26-circle packing, EurekAgent reports 2.635999, above the previous AI result 2.635986 and previous human result around 2.634.
- On Erdos minimum overlap, it reports 0.380870, lower than previous AI 0.380876 and previous human 0.380927.
- On first autocorrelation inequality, it reports 1.502861, slightly below previous AI 1.502863.
- On TriMul kernel engineering, the best median runtime is 2005.0307 us, ahead of the regraded leaderboard best at 2096.0441 us and TTT-Discover at 2247.7849 us.
- On the seven-task MLE-Bench Lite subset, EurekAgent reaches 85.71% any-medal, 71.43% gold, and 100% above median.
What builders should take from it
The practical takeaway is not to copy the headline number blindly. EurekAgent is useful when a team can reproduce the paper’s setup and when the measured bottleneck matches its own product or research loop. The paper-specific evidence above tells builders where the gain comes from, what comparator was used, and which parts are still protocol-dependent. A good follow-up is to rerun the same idea on a local task distribution before treating it as a general capability upgrade.
For agent builders, the most transferable piece is the separation between agent freedom and evaluator integrity. The agent can explore, write code, search the web, and inspect previous attempts, but it cannot edit the hidden grader or authoritative score files. That boundary is what turns a capable coding agent into a research worker rather than a script with too much filesystem access.
The second lesson is operational. Long-running discovery needs resumable state, ranked attempts, budget-aware interruption, and a way for humans to inspect transcripts without manually steering every step. Those are unglamorous product details, but they decide whether a run can be audited after it finds a surprising result.
Limits and open questions
The paper focuses on metric-driven tasks with executable evaluators. That is a strong fit for agents, but it excludes large parts of science where evidence is slow, noisy, or not reducible to a scalar score. Some comparisons are local regradings or selected subsets rather than one universal leaderboard. The environment-engineering thesis is plausible, but the result should be read as evidence for bounded optimization tasks, not a complete autonomous scientist.
The missing evidence that would change the judgment is a broader external replication: more independent harnesses, clearer release artifacts, and stress tests designed by groups that did not build the method. Until then, the paper is best read as a strong directional result with a concrete evaluation surface.
FAQ
What is EurekAgent?
EurekAgent is an environment-engineered system that coordinates CLI agents for metric-driven scientific discovery, using permissions, artifacts, budgets, and human oversight.
What results does EurekAgent report?
It reports new best numbers on three mathematics tasks, 2005.03 us median on TriMul, and 85.71% any-medal on a seven-task MLE-Bench Lite subset.
What is environment engineering in EurekAgent?
It means shaping the resources, constraints, interfaces, memory, evaluators, and budget controls around the agent so exploration stays productive and auditable.
One line: EurekAgent is strongest as a systems argument: for metric-driven science, the lab notebook, evaluator boundary, and budget controller may matter as much as the agent prompt. Read the original paper on arXiv.