Long Context · Language Models · AI Agents
From Context to Skills: Ctx2Skill Self-Evolves Context Learning
Ctx2Skill is a self-play framework that discovers natural-language skills from a long context with no human labels or external rewards, lifting GPT-4.1 from 11.1% to 16.5% and GPT-5.1 from 21.2% to 25.8% on CL-bench.
Quick answer
Ctx2Skill turns a long, technical context into reusable natural-language skills automatically, with no human-written skill annotations and no external reward signal. A Challenger-Reasoner-Judge self-play loop generates probing tasks, attempts them under an evolving skill set, and scores them with binary feedback. Plugging the mined skills back into a model lifts solving rates on CL-bench: GPT-4.1 goes from 11.1% to 16.5% and GPT-5.1 from 21.2% to 25.8%. The honest read: these are real, consistent gains across many backbones, but the absolute numbers are low — even the best assisted model clears only about a quarter of these context-learning tasks.
The problem: contexts that exceed parametric knowledge
Many real tasks hand a model a dense document — a rulebook, a protocol, a domain manual — and ask it to reason over knowledge that is not in its weights. The intuitive fix is “inference-time skill augmentation”: pull the rules and procedures out of the context into explicit skills the model can follow. Two things block that. First, hand-writing skills for long, technically dense contexts is prohibitively expensive. Second, and more interesting, there is no automatic signal telling you whether a proposed skill actually helps — unlike math or code, context learning has no verifier to check against. Ctx2Skill’s whole design is an answer to that missing feedback signal.
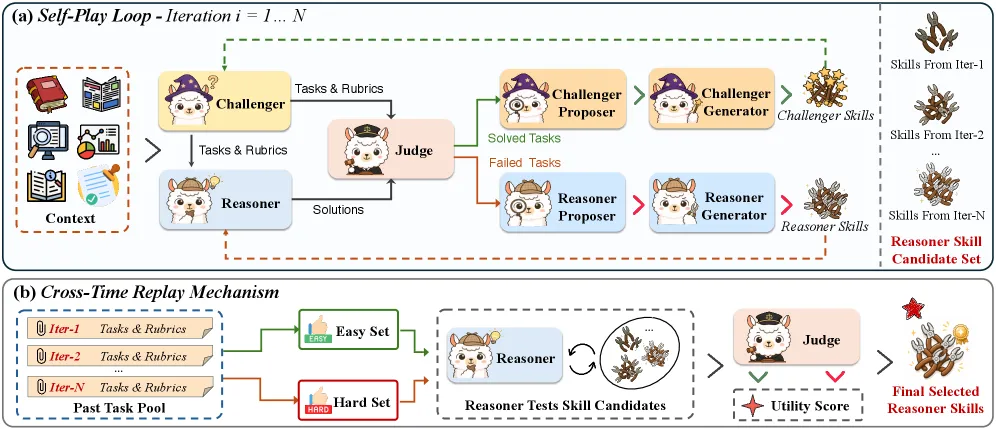
How the self-play loop manufactures its own feedback
Three agents run a loop over each context. A Challenger generates probing tasks and rubrics from the context. A Reasoner tries to solve them, guided by a skill set that grows over iterations. A neutral Judge returns binary pass/fail feedback. The clever part is that both the Challenger and the Reasoner evolve: dedicated Proposer and Generator agents read the failure cases and synthesize them into targeted skill updates for each side. So the system bootstraps its own training signal — failures become new skills, and the Challenger learns to probe harder while the Reasoner learns to cope. The loop runs N=5 iterations with M=5 tasks each, so roughly 25 Challenger-generated tasks per context drive the evolution.
Why it needs Cross-time Replay
Pure adversarial self-play degenerates. The Challenger drifts toward ever more extreme tasks, and the Reasoner over-specializes on skills that only fit late, pathological cases — “adversarial collapse.” Ctx2Skill counters this with a Cross-time Replay mechanism: instead of trusting the final skill set, it looks back across all iterations and picks the skill set that strikes the best balance over representative cases. Empirically, the early iterations are selected most often, with later iterations chosen more for contexts with complex knowledge structures. This is the part that makes the mined skills generalizable rather than overfit to the self-play tail, and it is the paper’s most defensible methodological contribution.
Key results
- GPT-4.1: solving rate rises from 11.1% to 16.5% on CL-bench with Ctx2Skill skills.
- GPT-5.1: rises from 21.2% to 25.8%, the strongest assisted result reported.
- Consistent across backbones: the paper reports the same direction of improvement on additional models including GPT-5.2, Claude Opus 4.5, Gemini 3 Pro, Kimi K2.5, and DeepSeek V3.2.
- Per-category gains (GPT-4.1): Procedural Task Execution improves about +7.2% and Domain Knowledge Reasoning about +6.2%, while Rule System Application gains a smaller ~+2.8%.
- Skill quality: human/automatic skill-quality scoring rates Ctx2Skill at 89.8/100, above an AutoSkill4Doc baseline at 86.2 and a plain prompting baseline at 81.8.
- CL-bench scale: 500 contexts, 1,899 tasks, and 31,607 rubrics, averaging 10.4K tokens per context and up to 65.0K tokens.
Limits and open questions
The absolute solving rates are the elephant in the room: a benchmark where the best assisted model scores 25.8% is brutally hard, and a +4 to +5 point lift, while consistent, leaves most tasks unsolved. The gains are also uneven — Rule System Application barely moves (~+2.8%), suggesting the skill format helps procedures more than rigid rule-following. Self-play is not free: 25 tasks per context across five iterations, each involving multiple agent calls, is a heavy inference budget to amortize per document. And because the Judge gives only binary feedback with no ground-truth verifier, the quality ceiling depends on the Judge being right — a self-generated signal can reinforce its own blind spots. Whether mined skills transfer across contexts, or must be re-mined per document, is the open question that decides how practical this is.
FAQ
What is Ctx2Skill?
Ctx2Skill is a self-evolving framework that automatically discovers, refines, and selects natural-language skills from a given context, with no human supervision and no external reward. The skills can be plugged into any language model to improve its context-learning ability.
How does Ctx2Skill work without external feedback?
Ctx2Skill manufactures its own feedback through a multi-agent self-play loop: a Challenger writes probing tasks, a Reasoner solves them with an evolving skill set, and a Judge gives binary pass/fail signals. Proposer and Generator agents turn failures into new skills, so the system improves without any verifier or human labels.
How much does Ctx2Skill improve LLM performance?
On CL-bench it lifts GPT-4.1’s solving rate from 11.1% to 16.5% and GPT-5.1’s from 21.2% to 25.8%, with consistent same-direction gains across other backbones such as GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro.
What is Cross-time Replay in Ctx2Skill?
Cross-time Replay prevents adversarial collapse by selecting, across all self-play iterations, the skill set that best balances performance over representative cases — rather than blindly keeping the final, over-specialized skills. Early iterations are chosen most often.
One line: Ctx2Skill bootstraps a feedback signal that context learning normally lacks, but the still-low absolute scores show how far context reasoning has to go. Read the original paper on arXiv.