Agent Memory · AI Agents · Retrieval-Augmented Generation
MRAgent: Graph Memory That Reconstructs Instead of Retrieves
MRAgent gives LLM agents a Cue-Tag-Content memory graph and lets the model reason while it traverses it, lifting LoCoMo LLM-Judge from 68.3 to 84.2 while cutting tokens to 118k per sample.
Quick answer
MRAgent is a memory layer for LLM agents that replaces one-shot retrieval with a reasoning loop over a graph. On LoCoMo with a Gemini-2.5-Flash backbone it raises the overall LLM-Judge score from 68.31 (Mem0, the strongest baseline) to 84.21, a 23.3% relative gain, and on LongMemEval it reaches 72.95 versus roughly 54-55 for every baseline. The unusual part: it is also the cheapest system tested, at 118k tokens per sample against A-Mem’s 632k and LangMem’s 3,268k. The gains live in the memory harness, not in a stronger base model. Same backbones drive the baselines.
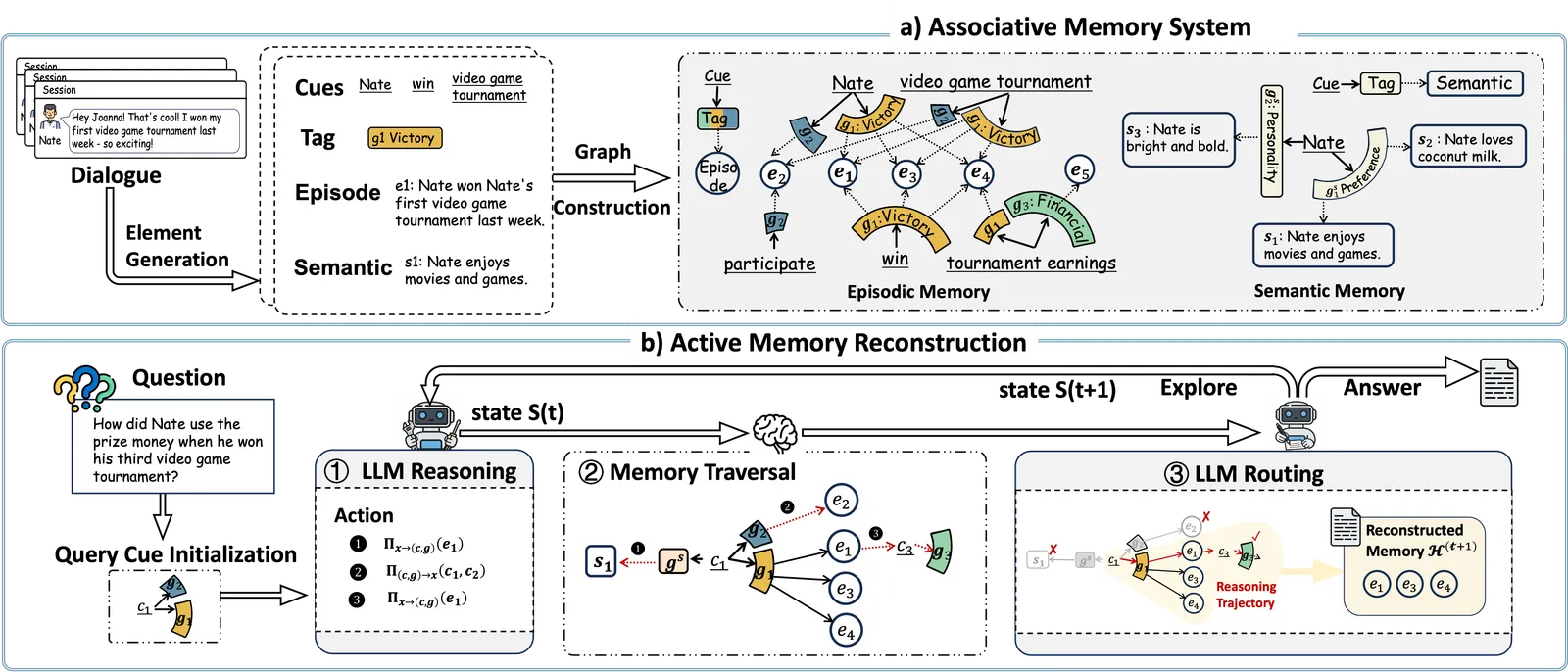
How the Cue-Tag-Content graph is built
The store is a heterogeneous graph, not a vector index. Three node types: cues (fine-grained keywords like entities or attributes), contents (the actual memory items), and tags that sit between them. A tag summarizes the associative relation linking a cue to a content node, so a triple reads (cue, tag, content). When the agent later searches, it first picks a few relevant tags, then pulls content conditioned on those tags. That two-stage move is what keeps large graphs tractable: tags let the model prune branches before it ever loads expensive episodic text.
Contents split into layers. The episodic layer holds event-specific units on a shared timeline, so temporal constraints can be applied during search. The semantic layer holds stable facts (preferences, attributes) anchored to a cue, reachable without scanning long histories. Construction is deliberately lightweight. The paper defers the heavy relation-building to query time, which is part of why its token bill is low.
How active reconstruction differs from retrieve-then-reason
Standard memory agents retrieve a fixed top-k or walk a predefined subgraph, then reason once over whatever came back. MRAgent interleaves the two. Each turn the LLM reads the query plus accumulated evidence, selects traversal actions, the graph expands those, and the LLM routes (keeps the relevant nodes, prunes the rest). It repeats until a checker decides the evidence answers the query.
The mechanism the authors lean on is mid-search cue discovery. In their running example a query about a video-game tournament only becomes answerable once the agent infers “July” as a temporal anchor from intermediate evidence and then finds the matching event. A passive retriever committing all its lookups upfront cannot do that. The paper backs this with a theorem: for retrieval budget T at least 2, the passive hypothesis class is strictly contained in the active one. An adaptive retriever can express anything a non-adaptive one can, and strictly more.
Key results
- LoCoMo, Gemini backbone: overall LLM-Judge 84.21 vs Mem0 68.31, a 23.3% relative gain. Temporal questions jump hardest, from Mem0’s 61.68 to 80.37.
- LoCoMo, Claude-Sonnet-4.5 backbone: overall 88.32 vs 78.61 (LangMem), about a 12.4% relative gain. The lift is smaller on the stronger backbone.
- LongMemEval, Gemini: 72.95 overall vs 53-55 for RAG, A-Mem, MemoryOS, LangMem, and Mem0. A mixed variant (Claude for retrieval, Gemini for construction) reaches 86.76, a 32% relative gain over the best baseline.
- Cost on LongMemEval: 118k tokens and 586s per sample, against A-Mem at 632k tokens and MemoryOS at 3,135s. MRAgent is best or near-best on both axes at once.
- Ablation on LoCoMo multi-hop: adding the reasoning loop beats structure-only retrieval across every graph variant; among structure-only variants, accuracy rises monotonically from Cue-Episode to Cue-Tag-Episode to Cue-Tag-Content.
- Multi-turn behavior: single-hop and temporal queries hit near-perfect recall within about three turns; multi-hop recall keeps climbing, gaining over 30% across successive steps.
Read those numbers as evidence about a memory system, not a model. The backbones (Gemini-2.5-Flash, Claude-Sonnet-4.5) are the same ones the baselines use, and the LLM-Judge scores come from GPT-4o-mini. The comparison is harness vs harness.
Why the cost and accuracy both improve
Most memory systems trade tokens for recall: they summarize history repeatedly and pre-compute dependencies at construction time. MRAgent inverts that. Construction stays cheap, and the expensive relational work happens only at query time, scoped to one question. Tags then act as a cheap filter, so the model reasons over short tag lists before touching full episodic content. The result is selective, on-demand access that avoids loading memories the query never needed. That is why a system doing more reasoning per query still ends up with the smallest token bill.
The ablation pins down where the gain comes from. The reasoning loop is the larger lever, not the graph shape: with-reasoning variants beat structure-only ones across the board. The Cue-Tag-Content structure helps mainly by giving that loop clean associative paths to follow and prune.
Limits and open questions
Both backbones are closed frontier models. There is no open-weight result, so it is unclear how much of the lift survives on a weaker LLM that may not infer cues like “July” reliably. The reasoning loop is only as good as the model running it.
The headline 86.76 on LongMemEval comes from a mixed setup (Claude for retrieval, Gemini for construction), which is a sensible engineering choice but not a like-for-like single-model number. The cleaner same-model figure is 72.95.
Scoring leans on GPT-4o-mini as judge alongside F1. LLM-Judge can reward fluent answers and inherit the judge’s biases, so the gap to baselines may read larger under one judge than another. Evaluation covers two conversational-memory benchmarks (LoCoMo, LongMemEval); whether reconstruction helps on tool-use logs, code histories, or non-dialogue agent memory is untested. Construction cost is also measured in tokens, not wall-clock latency for the indexing pass, which matters for live agents.
FAQ
What is the Cue-Tag-Content graph in MRAgent?
It is MRAgent’s memory store: a graph where cues (keywords), contents (memory items), and tags (the relation summarizing how a cue links to a content) form triples. At query time the agent selects tags first, then fetches content conditioned on them, which lets it prune branches before loading expensive episodic text.
How much does MRAgent beat Mem0 on LoCoMo?
On LoCoMo with a Gemini-2.5-Flash backbone, MRAgent scores 84.21 overall on LLM-Judge versus 68.31 for Mem0, a 23.3% relative gain. On a Claude-Sonnet-4.5 backbone the relative gain narrows to about 12.4%.
Does reconstruction beat retrieval because of the model or the memory harness?
The harness. MRAgent uses the same frozen backbones (Gemini-2.5-Flash, Claude-Sonnet-4.5) as its baselines; the gains come from the Cue-Tag-Content graph plus the active reconstruction loop, and the ablation shows the reasoning loop contributes more than the graph structure alone.
Why is MRAgent cheaper than A-Mem and LangMem if it does more reasoning?
MRAgent keeps construction lightweight and defers relation-building to query time, scoped to one question, while tags filter out irrelevant branches before episodic content is loaded. It uses 118k tokens per sample on LongMemEval versus A-Mem’s 632k and LangMem’s 3,268k.
What are the main limitations of MRAgent?
It is only tested on two closed frontier backbones with no open-weight result, its best LongMemEval number (86.76) uses a mixed-backbone setup rather than one model, scoring relies on a GPT-4o-mini judge, and evaluation is limited to dialogue-memory benchmarks rather than tool or code histories.
One line: MRAgent shows that letting an LLM reason while it walks a graph memory beats fixed retrieval on long-conversation tasks, and does so more cheaply, but the evidence is two dialogue benchmarks on closed models. Read the original paper on arXiv.