Video Generation · Diffusion Models · Multimodal Models
OmniDirector: Multi-Shot Camera Cloning without Cross-Paired Data
OmniDirector copies camera motion from a reference video into new generations and cuts rotation error to 2.64 degrees, beating CamCloneMaster (4.11), with no cross-paired training data.
Quick answer
OmniDirector clones the camera movement of any reference video into a freshly generated video, and it does so without the cross-paired datasets every prior method needed. On the authors’ 1,094-sample evaluation set it cuts rotation error (RRE) to 2.64 degrees against CamCloneMaster’s 4.11, and lifts rotation precision to 83.18% versus 74.14%. The bigger jump is multi-shot: it scores 96.52% temporal precision on shot transitions where CamCloneMaster manages 2.20%. The trick is representing the camera path as a rendered grid video instead of pose matrices or text, which lets the model build its own training pairs from 1.8 million ordinary internet videos.
The cross-paired data wall it gets around
Camera cloning means taking the motion from one clip (a slow dolly-in, a whip pan, an orbit) and reapplying it to new content. The standard recipe needs cross-paired data: two videos with identical camera moves but different scenes, so the model learns to separate motion from content. That data barely exists. Filming the same trajectory twice over different subjects does not scale, and synthetic substitutes leave a domain gap.
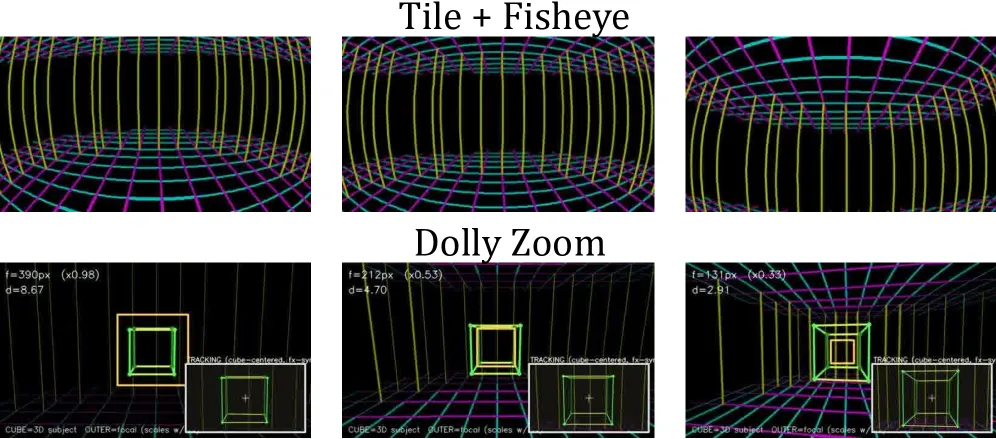
OmniDirector sidesteps the requirement by changing the camera representation. It renders the camera trajectory as a “camera grid”: an empty 3D room where red and blue orthogonal lines mark ceiling and floor, yellow vertical lines mark walls, and a tube traces the path. Because this grid is computed directly from any video’s estimated camera parameters, every clip becomes its own training pair. The model sees the grid plus a reference frame and learns to produce a video whose camera follows the grid. No matched second video is needed.
How the grid drives generation
The backbone is a multi-modal diffusion transformer. It concatenates the reference image, the camera grid, and the noisy video latent along the frame dimension, then lets visual and text tokens attend through separate pathways. A detail worth flagging: 30% of training samples are self-reconstruction, where the model rebuilds the grid from grid conditioning, which forces it to actually read the geometry rather than hallucinate plausible motion.
Two other pieces matter. The grid encodes hard-to-describe effects directly: fisheye distortion via the Kannala-Brandt model, and dolly zoom through focal-length proportionality. And an adaptive classifier-free guidance schedule injects the grid during high-noise steps (when global motion is set) and the other signals during low-noise steps (when detail resolves). Ablating that schedule drops rotation precision from 83.18% to 74.55%.
Key results
- Rotation error (RRE): 2.64 degrees vs 4.11 (CamCloneMaster), 5.67 (LTX-LoRA), 8.33 (Seedance 2.0), on the 1,094-sample web evaluation set. Lower is better.
- Translation precision (T-Pre): 72.74% vs 52.21% for CamCloneMaster, a 20-point gap on getting the camera position right.
- Multi-shot temporal precision (Tem-Pre): 96.52% (transition placed within 3 frames) vs 2.20% for CamCloneMaster and 38.94% for LTX-LoRA. This is where the method separates from the pack, not on single-shot accuracy.
- Content leakage: 0.51% frame leakage and 3.38% shot leakage vs 1.60% and 11.59% for CamCloneMaster, meaning less of the reference video’s content bleeds into the output.
- Human preference (GSB vs CamCloneMaster): 88.52% Good-or-Same on camera, 95.69% on quality, 94.26% on narrative.
The single-shot rotation and translation gains are real but incremental. The headline is the multi-shot result. Prior cloning methods essentially cannot reproduce a cut and its new camera setup; OmniDirector renders transition frames as pure white and generates separate inter-shot and intra-shot camera prompts, which is why temporal precision jumps from low single digits to the mid-90s.
What the numbers do not prove
The 96.52% temporal precision uses a sub-3-frame error threshold, so it measures whether a cut lands near the right moment, not whether the resulting two shots are cinematically coherent over long durations. The authors are explicit about the ceiling: token concatenation “struggles to maintain long-term memory and temporal consistency when scaling to significantly longer video sequences.” So this is strong for short multi-shot clips, unproven for minute-scale sequences.
Read the camera-accuracy metrics with the estimator in mind. Both the training labels and the evaluation use DPA-V3 for camera extrinsics and approximate focal length as 0.8 times the longer image side. A model trained and scored against the same estimation pipeline can inherit that pipeline’s systematic biases, which the metrics would not reveal.
Limits and open questions
The long-video limitation is the one to watch. Camera cloning is most useful for full scenes and sequences, exactly where token concatenation degrades. The reported results are on 480p clips, so resolution and duration headroom are both open.
The dataset is 1.8 million internet videos (movies, ads) filtered with TransNet-V2 for shot detection. That distribution is heavy on professional cinematography, which helps quality but means the camera-move vocabulary reflects what film and advertising shoot, not arbitrary user intent. Neither the dataset nor model weights are confirmed as released in the paper, so independent reproduction of the leakage and multi-shot numbers is not yet possible.
The emergent abilities (driving motion from raw RGB or Canny edge sequences without retraining) are shown as qualitative generalization, not quantified, so treat them as promising demos rather than benchmarked capabilities.
FAQ
How does OmniDirector clone camera motion without cross-paired data?
It renders each video’s camera trajectory as a 3D grid (an empty room with colored lines marking floor, ceiling, walls, and a tube for the path) computed from estimated camera parameters. Because the grid comes from the same single video, every clip is its own training pair, removing the need for two videos with matched camera moves.
How does OmniDirector compare to CamCloneMaster on accuracy?
It reports 2.64-degree rotation error versus CamCloneMaster’s 4.11, and 72.74% translation precision versus 52.21%. The decisive gap is multi-shot temporal precision: 96.52% versus 2.20%, because CamCloneMaster was not built to reproduce shot transitions.
Why is OmniDirector’s 96.52% temporal precision not the whole story?
That score uses a sub-3-frame threshold for placing a cut, so it measures transition timing, not long-term coherence across shots. The authors note that the token-concatenation design loses temporal consistency on much longer sequences, and all results are at 480p, so long high-resolution multi-shot generation remains untested.
Who should use OmniDirector and who should wait?
Teams building short-form video tools where users want to copy a specific camera move (and especially multi-shot edits) should look at the grid representation now. Anyone needing minute-long, high-resolution, consistent sequences should wait, since the paper flags long-term memory as the open bottleneck.
One line: OmniDirector makes camera cloning practical by turning the camera path into a grid the model can self-supervise on, winning clearly on multi-shot transitions while staying bounded to short 480p clips. Read the original paper on arXiv.