AI Agents · LLM Reasoning · Fine-Tuning & Adaptation
Skill1: One RL Policy That Selects, Uses, and Distills Agent Skills
Skill1 trains a single Qwen2.5-7B policy to retrieve, apply, and create reusable skills under one task-outcome reward — reaching 97.5% on ALFWorld, 6.5 points over the strongest RL-only baseline.
Quick answer
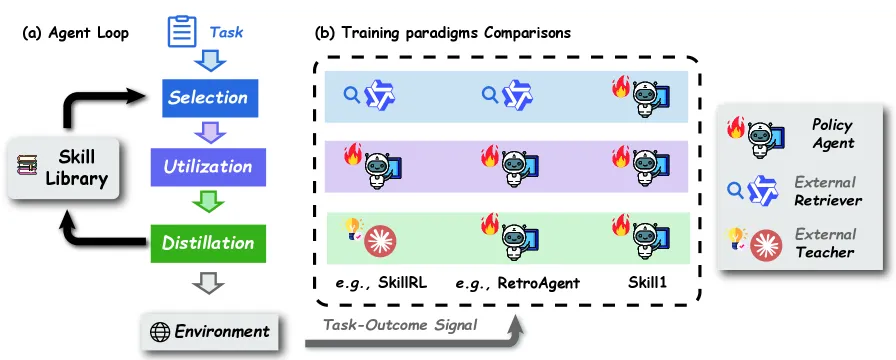
Skill1 trains one reinforcement-learning policy to do three jobs that prior work optimized separately: retrieve relevant skills from a library, apply them while solving a task, and distill new skills from successful trajectories. All three are driven by the same task-outcome reward via GRPO. On ALFWorld the unified policy reaches a 97.5% average success rate, beating the strongest RL-only baseline (GiGPO at 90.8%) by 6.5 points, and on WebShop it scores 89.7 with an 82.9% success rate — all on a single Qwen2.5-7B-Instruct backbone.
Why “skill-augmented” agents kept breaking
The appeal of a skill library is obvious: an agent that solved a task once should not relearn it from scratch. The problem is that the three operations on that library — picking the right skill, using it well, and writing a good new skill — were trained or hand-engineered in isolation. A retriever tuned for embedding similarity does not know whether the skill it surfaced actually helped the downstream policy; a distillation step that summarizes a trajectory does not get feedback on whether the resulting skill is ever reused successfully. Skill1’s argument is that this separation is the bug: each component optimizes a proxy objective, and the proxies do not compose into good end-to-end behavior.
How the unified policy works
Skill1 folds selection, utilization, and distillation into one policy and ties them to a shared signal — did the task succeed. Concretely, the agent runs a loop: given a task it retrieves candidate skills, the policy conditions on them to act in the environment, and after the episode it can distill a new skill back into the library. Training uses GRPO (Group Relative Policy Optimization) with a group size of 16 rollouts per task and a learning rate of 1e-6, on a frozen all-MiniLM-L6-v2 encoder (384-dimensional) for the skill embeddings. Two auxiliary losses with weight 0.3 each shape selection and distillation, and skill utility is tracked with an exponential moving average (rate 0.05) so the library can prune what never pays off, capped at 5,000 skills.
The honest framing is that the novelty is not a new RL algorithm — GRPO is borrowed from the reasoning-model literature. The contribution is the credit-assignment design: routing one outcome reward through all three skill operations so they co-adapt instead of fighting.
Key results
- ALFWorld: 97.5% average success, with per-category rates of 100.0% (Pick), 98.6% (Look), 97.3% (Clean), 99.2% (Heat), 96.1% (Cool), and 96.0% (Pick2).
- +6.5 points over GiGPO, the strongest RL-only baseline (90.8%); also ahead of RetroAgent (94.9%) and SkillRL (89.9%) on the same benchmark.
- WebShop: 89.7 score, 82.9% success rate, showing the method transfers beyond embodied household tasks to web navigation.
- Ablations confirm every part earns its keep. Removing the skill library drops ALFWorld from 97.5% to 80.9% (−16.6). Removing selection costs 5.7 points (91.8%); removing distillation costs 5.1 (92.4%). Zeroing the selection auxiliary loss (lambda1=0) gives 94.0%, and zeroing the distillation loss (lambda2=0) gives 94.9%.
- Cost is modest: training converges in 100-150 steps, roughly 30 hours on 8 NVIDIA H800-80GB GPUs for ALFWorld.
The biggest single number is the library ablation: −16.6 points when the library is removed says most of the gain comes from accumulating and reusing skills, not from the RL polish alone.
Why this matters now
Agent research in 2026 is converging on the idea that experience should compound — that an agent should get better at a task family the more it sees of it. Skill1 is a clean datapoint that the way to make a skill library actually compound is to train its operations jointly under the real objective, not to bolt a frozen retriever onto a frozen policy. That lesson generalizes beyond these two benchmarks, even if the numbers do not.
Limits and open questions
The evaluation is narrow. ALFWorld and WebShop are both well-trodden, relatively structured environments with clear success signals — exactly the setting where outcome-reward RL works best. Whether the same co-evolution helps in open-ended, sparse-reward, or long-horizon real-world agent tasks is untested here. The backbone is a single 7B model, so it is unclear how the unified-policy advantage scales with model size, or whether a much stronger base model would close the gap with simpler baselines. The 5,000-skill cap and EMA pruning are reasonable engineering but unprincipled — there is no analysis of what happens as the library saturates or when skills conflict. And as with most outcome-reward methods, success depends on a checkable reward, which most messy real tasks do not provide.
FAQ
What is Skill1 and what problem does it solve?
Skill1 is a reinforcement-learning framework that trains one policy to retrieve, apply, and create reusable skills for a language-model agent. It solves the failure mode where these three operations, optimized separately, do not compose into good end-to-end behavior.
How does Skill1 differ from a retrieval-augmented agent?
A retrieval-augmented agent uses a fixed retriever scored on embedding similarity. Skill1 trains selection, utilization, and skill distillation together under one task-outcome reward, so the retriever learns what actually helps the policy rather than what merely looks similar.
What benchmarks does Skill1 report and how strong are the results?
On ALFWorld, Skill1 reaches 97.5% average success, 6.5 points above the strongest RL-only baseline (GiGPO, 90.8%). On WebShop it scores 89.7 with an 82.9% success rate, using a Qwen2.5-7B-Instruct backbone.
Does Skill1 introduce a new RL algorithm?
No. Skill1 uses GRPO, the same group-relative policy optimization popular in reasoning-model training. The contribution is the credit-assignment design that routes one outcome reward through all three skill operations.
What are the main limitations of Skill1?
It is tested only on two structured benchmarks (ALFWorld and WebShop), on a single 7B model, and depends on a checkable task-outcome reward. Its behavior at larger scale, on open-ended tasks, and as the skill library saturates remains unexplored.
One line: tie skill selection, use, and distillation to one outcome reward and a 7B agent’s library actually compounds. Read the original paper on arXiv.