Diffusion Models · Video Generation · World Models
Stream-R1: Reliability-Perplexity Aware Reward Distillation Explained
Stream-R1 reweights DMD losses by video reward scores and per-region perplexity instead of treating signals equally. Its 1.3B streaming model hits 84.40 VBench at 23.1 FPS, beating its 14B teacher's 84.26 for free.
Quick answer
Stream-R1 makes streaming video distillation pay attention to where the supervision matters. Instead of optimizing every rollout frame and every pixel with equal weight, it rescales losses by two signals: how reliable each generated rollout is (a pretrained video reward score) and how uncertain each spatial-temporal region is (perplexity). On VBench the 1.3B student reaches a total score of 84.40, edging past its 14B teacher Wan2.1’s 84.26 and the Reward Forcing baseline at 84.13 — at 23.1 FPS, with no architecture change and no added inference cost.
The problem: distillation that wastes its signal
Autoregressive streaming video diffusion generates a video chunk by chunk so you can watch it stream in real time. To make that fast, the heavy multi-step teacher is distilled into a few-step student via distribution matching distillation (DMD). The catch the authors target: standard DMD treats all supervision as equally informative. Every sampled rollout contributes the same weight to the loss, and within each frame every region is optimized the same way — even though some rollouts are near-garbage and some regions (fast motion, fine texture) are exactly where the student is failing while flat backgrounds are already fine.
That uniform treatment is the leak. Gradient budget gets spent on rollouts and regions that have little left to teach, while the hard cases get diluted. Stream-R1’s bet is that you can recover quality for free by simply reweighting the existing objective — no new data, no bigger model, no slower inference.
How the two-level reweighting works
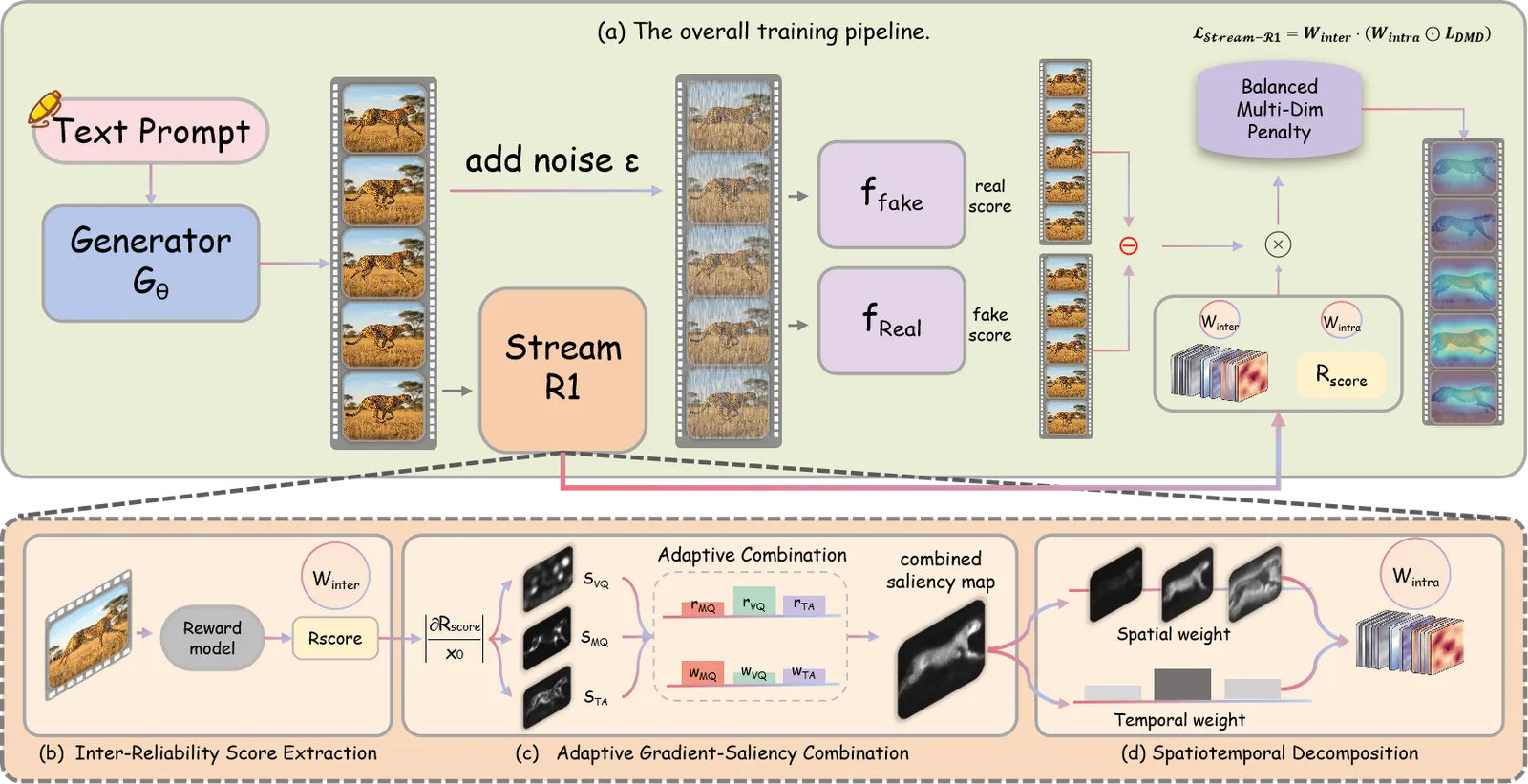
The framework, Reliability-Perplexity Aware Reward Distillation, splits the idea across two axes.
Inter-Reliability (across rollouts). Each generated rollout is scored by a pretrained video reward model, and that score rescales the rollout’s contribution to the distillation loss. High-quality rollouts — the ones the reward model trusts — carry more weight; unreliable ones are down-weighted so they stop dragging the student toward bad modes. This is the “which sample to trust” axis.
Intra-Perplexity (within a rollout). Inside each rollout, the loss is concentrated on the spatial and temporal regions where refinement yields the largest gains, measured by perplexity. The high-uncertainty regions — typically where motion is complex or detail is dense — get more optimization pressure; regions the student already predicts confidently get less. This is the “which part of the frame to focus on” axis.
Combined, the student learns harder from trustworthy rollouts and concentrates effort on its weak regions. Crucially, both signals operate purely at training time on the loss weights, so the deployed model is identical in size and speed to a plain DMD student.
Key results
Numbers below are from the paper’s evaluation; the student is Wan2.1-T2V-1.3B distilled from the Wan2.1-T2V-14B teacher at 832×480.
- VBench (5s short video): Stream-R1 total 84.40 (quality 85.14, semantic 81.44), above the 14B teacher Wan2.1 at 84.26 and the Reward Forcing baseline at 84.13. A 1.3B few-step student beating its own 14B multi-step teacher on the aggregate score is the headline.
- Inference speed: 23.1 FPS at 832×480 with denoising steps
[1000, 750, 500, 250]and 3 latent frames per chunk — real-time streaming, unchanged by the method. - Long 60s video (Qwen3-VL judge): visual quality 4.92, motion dynamics 4.04, text alignment 4.11 — gains hold when generation runs far past the short-clip training horizon.
- Human preference (50 videos, 60s): dynamic reasonableness win rate 63.0%, visual quality 60.0%, overall preference 57.0% against the baseline.
- Training cost: 1,000 optimizer steps on 8 A100s, effective batch size 64, about 56 hours — modest for a video model.
The honest read: the VBench margin over the teacher is thin (84.40 vs 84.26), so the stronger evidence is the long-video and human-preference gaps, where the reweighting compounds over a 60-second rollout rather than a 5-second one.
Why this matters now
Streaming, real-time video generation is the direction the field is pushing toward — interactive worlds, live avatars, game-like rollouts — and the bottleneck is doing it cheaply enough to run few-step. Stream-R1’s contribution is that it improves the training objective rather than the architecture, so the gains are free at inference. That makes it a drop-in idea: any DMD-based streaming pipeline can in principle add reliability and perplexity weighting without touching the deployed model.
Limits and open questions
The approach inherits the reward model’s blind spots. Inter-Reliability is only as good as the pretrained video reward score it trusts; if that reward model is biased or game-able, the reweighting amplifies the bias. The VBench improvement over the teacher is small enough to sit near noise, so the case rests heavily on the 60-second human-preference results, which come from just 50 videos. Everything is shown on a single backbone (Wan2.1, 1.3B student / 14B teacher) at one resolution — there is no evidence yet that the two-level weighting transfers to other distillation recipes or larger students. And perplexity-based region weighting adds training-time bookkeeping; the paper reports no slowdown at inference, but the training overhead versus plain DMD is not the focus.
FAQ
What is Stream-R1?
Stream-R1 is a reward-distillation framework for streaming (autoregressive, chunk-by-chunk) video diffusion. It reweights the distribution matching distillation loss using two signals — per-rollout reliability from a video reward model and per-region perplexity — so a few-step student trains harder on trustworthy samples and its own weak regions.
How does Stream-R1 beat its teacher?
On VBench the 1.3B Stream-R1 student scores 84.40 total versus 84.26 for the 14B Wan2.1 teacher. The reweighting lets the few-step student focus optimization where it counts; the margin is narrow on short clips but widens on 60-second video and human preference (57.0% overall win rate).
Does Stream-R1 slow down inference?
No. Both the reliability and perplexity signals only change loss weights during training. The deployed student is identical in size (1.3B) and speed (23.1 FPS at 832×480) to a standard DMD student — there is no architecture change and no added inference cost.
What models and benchmarks does Stream-R1 use?
The student is Wan2.1-T2V-1.3B distilled from Wan2.1-T2V-14B at 832×480, trained for 1,000 steps on 8 A100s. Evaluation uses VBench for 5-second clips, a Qwen3-VL judge for 60-second videos, and a 50-video human preference study.
One line: don’t generate more — weight the loss you already have by which samples to trust and which regions are hard. Read the original paper on arXiv.