LocateAnything:并行框解码让视觉定位更快
LocateAnything 把整个检测框一步解出,而非逐位输出坐标,混合模式达每秒 12.7 个框,约为 Rex-Omni-3B 的 2.5 倍,3B 规模下领跑 COCO 与 LVIS。
快速答案
LocateAnything 是 NVIDIA 的视觉语言定位模型,它把一个检测框整体一步解出,而不是把坐标当成一串数字 token 逐位生成。仅此一处改动,就把混合模式下的吞吐推到每秒 12.7 个框——约为最接近的前作 Rex-Omni-3B(每秒 5.0 个)的 2.5 倍,约为基于文本的 Qwen3-VL(每秒 1.1 个)的 10 倍——而这个 3B 模型在 COCO 上仍以 54.7 mean F1@mIoU、LVIS 上以 50.7 居首,在同等参数量下击败 Rex-Omni。
为什么「坐标当文本」是瓶颈
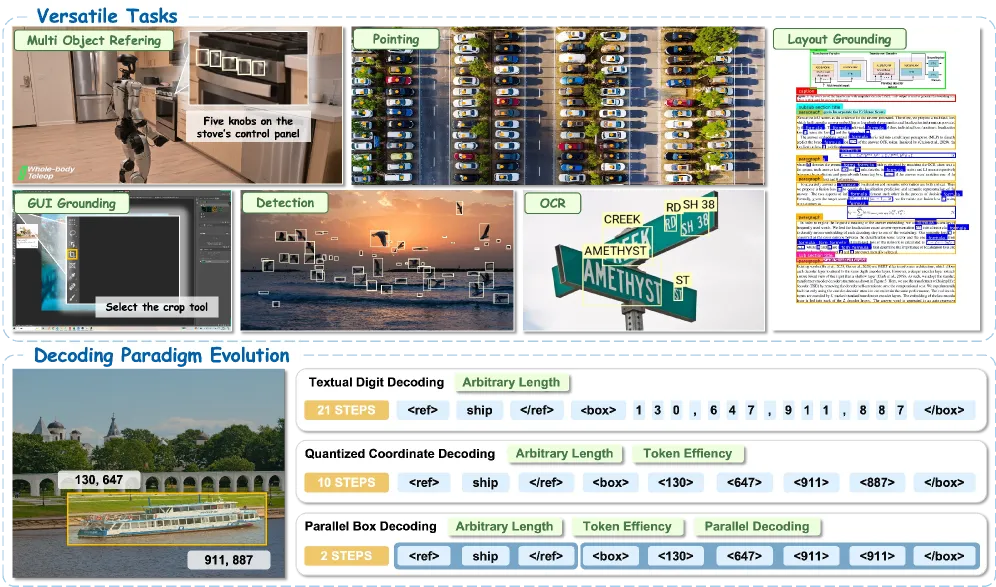
让多模态大模型「指出」物体,主流做法是把坐标写成文本:一个框变成 130, 647, 911, 887 这样的字符串,模型一次输出一个数字 token。能用,但又慢又脆。单个框可能要十几步自回归;而且每位数字独立采样,一个框的四个数无法保证几何一致,模型可能在框中途「跑偏」。场景里物体一多,步数随框数线性爆炸,密集检测就慢得难受。
LocateAnything 的前提是:框是一个几何对象,不是一句话,应当作为整体一步解出。
并行框解码怎么工作
并行框解码(Parallel Box Decoding,PBD)把每个几何元素——一个检测框或一个点——当成单个类 token 单元,在一步里输出,而不是把坐标拆成数字序列。由此带来两点。其一,框的四个角一起产出,框内几何一致性是天生保证的,而非靠运气。其二,多个框可以并行解码,这正是吞吐提升的来源:代价不再随「每框几位数字」增长,而随物体数量平缓增长。
系统用 Moon-ViT 视觉编码器搭配 Qwen2.5 语言主干,规模 3B,并提供三种解码模式——快速模式每秒 15.3 个框、混合模式 12.7、慢速模式 4.3——让你不换模型就能在速度与质量间权衡。
LocateAnything-Data 里有什么
模型训练在作者自建的语料 LocateAnything-Data 上:1.38 亿条自然语言查询,覆盖 1200 万张唯一图像,标注了 7.85 亿个检测框。这种规模的意义在于广度——同一个模型可处理多目标指代、指点、版面定位、GUI 定位、检测以及 OCR 式定位,而非局限于某个窄基准。这既是解码器贡献,也是数据集贡献,而其体量本身就是护城河:没有可比的定位数据,复现 PBD 大概率刷不出这些数字。
关键结果
- COCO 检测: 3B 规模下 54.7 mean F1@mIoU,为论文主表最高。
- LVIS 检测: 50.7 mean F1@mIoU,同样在 3B 领先;作者报告在同等参数量下 LVIS 约 +3.8%、COCO mean F1 约 +1.8% 优于 Rex-Omni-3B。
- RefCOCOg 指代: val 76.7 F1@mIoU,test 77.6。
- 吞吐: 每秒 15.3 个框(快速)、12.7(混合)、4.3(慢速)——对比 Rex-Omni-3B 的 5.0 与文本式 Qwen3-VL 的 1.1,分别约快 2.5 倍与 10 倍。
真正的看点不是某项精度纪录,而是这份提速在同等模型规模下没有付出精度代价。
为什么现在重要
定位吞吐正成为智能体与具身系统的限速环节。一个要定位每个可点击元素的 GUI 智能体,或一个每帧需要多物体框坐标的机器人策略,大部分延迟预算都耗在坐标解码上。PBD 正面攻击这块开销;而且它建在标准的 Qwen2.5 + ViT 栈上,意味着思路可移植,而非绑死在定制架构。若并行解码这招能泛化,「输出几何,别逐字拼写」有望成为定位头的默认做法,正如结构化输出成了工具调用的默认。
局限与存疑
报告的优势是 F1@mIoU,而非多数 RefCOCO 榜单用的经典 [email protected],因此与较早的定位工作直接对比要小心——指标不可直接互换。所有结果都在 3B 规模下给出;论文未说明并行解码的优势在 7B 以上是否保持、缩小还是扩大,而那里文本式解码器可能把质量差距追回。三模式设计虽方便,却暗示最快档以质量换速度。论文的论证又依赖其专有的 1.38 亿框数据集,外部团队无法干净地区分「PBD 更好」还是「我们用了多得多的定位数据」。在公开数据上的独立复现是显而易见的下一步检验。
常见问题
LocateAnything 为什么比其他定位模型快?
LocateAnything 把每个检测框作为整体一步解出(并行框解码),而非逐位输出坐标,混合模式达每秒 12.7 个框,对比 Rex-Omni-3B 的 5.0 与文本式 Qwen3-VL 的 1.1。
LocateAnything 是用速度换精度吗?
不是,至少在同等模型规模下:3B 模型在 COCO(54.7 mean F1@mIoU)与 LVIS(50.7)上领先,分别约 +1.8% 与 +3.8% 优于 Rex-Omni-3B,同时快约 2.5 倍。
LocateAnything 的并行框解码是什么?
这是一种解码方案,把检测框或点当成单个几何单元,把所有坐标在一步里一起产出。它保证框内一致性,并让多个框并行解码,而非随每框数字位数增长。
LocateAnything 用什么数据训练?
LocateAnything-Data:1.38 亿条自然语言查询、1200 万张唯一图像、7.85 亿个标注框,涵盖指代、指点、版面、GUI、检测与 OCR 定位。
LocateAnything 是谁做的?
它来自 NVIDIA 的团队,建在 Moon-ViT 视觉编码器与 Qwen2.5 语言主干之上,规模 3B。
一句话:解出整个框,别逐字拼坐标——定位就能在不掉精度的前提下快约 2.5 倍。阅读 arXiv 原文。