LongLive-2.0:用 NVFP4 4 比特训练与推理长视频
LongLive-2.0 让 5B 长视频模型全程跑在 NVFP4 4 比特上,720p 达 45.7 FPS,训练快 2.1 倍、推理快 1.84 倍,VBench 仅降半分。
快速答案
LongLive-2.0 是首个把长视频扩散模型的训练与推理全程跑在英伟达 NVFP4 4 比特格式上的系统,而且没有出现常见的质量崩塌。这个 5B 模型在 2 步设置下于 1280x720 达到 45.7 FPS,训练比 BF16 快达 2.1 倍、推理快 1.84 倍;同时 VBench 总分仅从 BF16 的 85.06 滑到 NVFP4 4 步的 84.51——一条 4 比特管线只掉了约半分。
为什么 4 比特长视频是最难的场景
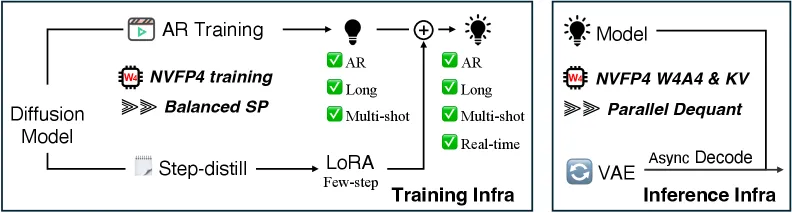
把推理量化到 4 比特如今很常见,但把整条长视频的训练加推理栈都压到 4 比特并不常见。长视频是低精度的最坏情形,因为误差会累积:自回归模型用自己前面的输出作为下一段的条件,4 比特里每步的微小舍入误差会在 60 秒片段里层层叠加,表现为漂移、闪烁和身份丢失。再加上训练长片段会撑爆单卡显存,所以必须用序列并行(SP)——而朴素 SP 会浪费算力,因为干净(已去噪)和带噪的隐变量块在各 rank 上分布不均。LongLive-2.0 的贡献,就是让 NVFP4 同时扛住这两重压力。
Balanced SP 与 NVFP4 如何配合
训练侧把两个想法拼在一起。Balanced SP 在每张 GPU 上把一个干净隐变量块和一个带噪块配对,既让 teacher-forcing 掩码保持自然,又把每 rank 的 VAE 编码从 O(F) 压到接近 O(F/P + h)(F 为帧数,P 为 SP 度,h 为小幅 halo)。正是这种再平衡,把原本爆显存的 BF16 跑成了可训练,也贡献了大部分训练加速。随后 NVFP4 用分层缩放把权重和激活量化到 E2M1 4 比特浮点——FP4 数值、FP8 块缩放、FP32 张量缩放——让矩阵乘跑在 Blackwell 的 4 比特 Tensor Core 上。论文还用分布匹配蒸馏直接微调扩散模型,而不是先从 ODE 求解器初始化,从而让少步学生模型在 4 比特下保持稳定。
推理:W4A4 加流式 VAE
推理时模型跑 W4A4(权重与激活均 4 比特),并加两个省显存手法。KV 缓存被重排后以 NVFP4 微块缩放独立量化,在 2% 以内的开销下实现约 3.6 倍 KV 压缩;异步流式 VAE 让解码块与去噪并行执行,使解码显存占用从 O(C·Tc) 降到接近 O(Tc)。在 GB200 上生成 64 秒视频的综合效果就是那条头条数字:BF16 需要 112.9 GB、36.4 秒,而 2 步 NVFP4 路径只需 36.3 GB、19.4 秒。
关键结果
- 吞吐: NVFP4 2 步设置在 1280x720 达 45.7 FPS;NVFP4 4 步为 29.7 FPS,而 BF16 4 步为 24.8 FPS。
- 质量代价: VBench 总分从 85.06(BF16)到 84.51(NVFP4 4 步)再到 83.14(NVFP4 2 步);画质子分稳在 86.43 对 86.67。
- 训练: 64 秒一次迭代从 1196.5 秒(BF16 Balanced SP)降到 639.5 秒(NVFP4 Balanced SP),约 2.1 倍加速;不带 SP 的纯 BF16 直接爆显存。
- 推理显存/时延: GB200 上 64 秒生成从 112.9 GB / 36.4 秒(BF16)降到 36.3 GB / 19.4 秒(2 步 NVFP4),端到端约 1.84 倍。
- KV 缓存: 约 3.6 倍压缩,开销低于 2%;蒸馏显存为 BF16 的 0.69 倍(49.0 GB 对 70.5 GB)。
- 长片一致性: 在 VBench-Long 的 60 秒片段上,主体一致性保持在 97.48%(BF16)与 97.62%(NVFP4)。
局限与存疑
速度数字被硬件锁死。NVFP4 需要带原生 4 比特 Tensor Core 的英伟达 Blackwell 级 GPU;在 A100 或 H100 上没有 NVFP4 路径,作者改用序列并行推理兜底,所以不在 Blackwell 上的人只拿到工程,拿不到 4 比特加速。质量差距在 4 步时虽小,到 2 步时却拉大——最快的 45.7 FPS 模式恰恰是 VBench 总分掉近两分、语义子分跌得最狠(76.81 到 74.12)的地方,所以头条 FPS 与头条质量并非同一配置。作为一篇系统论文,它的胜处是吞吐与显存,而非新的生成能力:底层视频模型仍是同一家族,所以它对已经在 Blackwell 上做长视频的团队意义最大,对研究生成质量本身的人意义则小得多。
常见问题
LongLive-2.0 是什么?
LongLive-2.0 是英伟达及合作者提出的 NVFP4 4 比特并行基础设施,把 5B 长视频扩散模型的整条训练与推理流程跑在 4 比特上,在 720p 达 45.7 FPS,VBench 较 BF16 仅降约半分。
LongLive-2.0 比 BF16 快多少?
LongLive-2.0 训练快达 2.1 倍(64 秒一次迭代从 1196.5 秒降到 639.5 秒),推理约快 1.84 倍,把 GB200 上 64 秒生成从 36.4 秒降到 19.4 秒、从 112.9 GB 降到 36.3 GB。
LongLive-2.0 的 NVFP4 会损伤视频质量吗?
4 步时只轻微下降:VBench 总分从 85.06(BF16)到 84.51(NVFP4)。更快的 2 步模式代价更大,总分降到 83.14,语义分从 78.63 跌到 74.12。
LongLive-2.0 需要什么硬件?
NVFP4 加速需要带 4 比特 Tensor Core 的英伟达 Blackwell GPU(如 GB200)。A100 或 H100 没有原生 NVFP4 支持,作者用序列并行推理作为兜底。
一句话:NVFP4 4 比特能几乎无损地端到端撑起整个长视频模型——前提是你在 Blackwell 上。阅读 arXiv 原文。